在Coze智能体中——
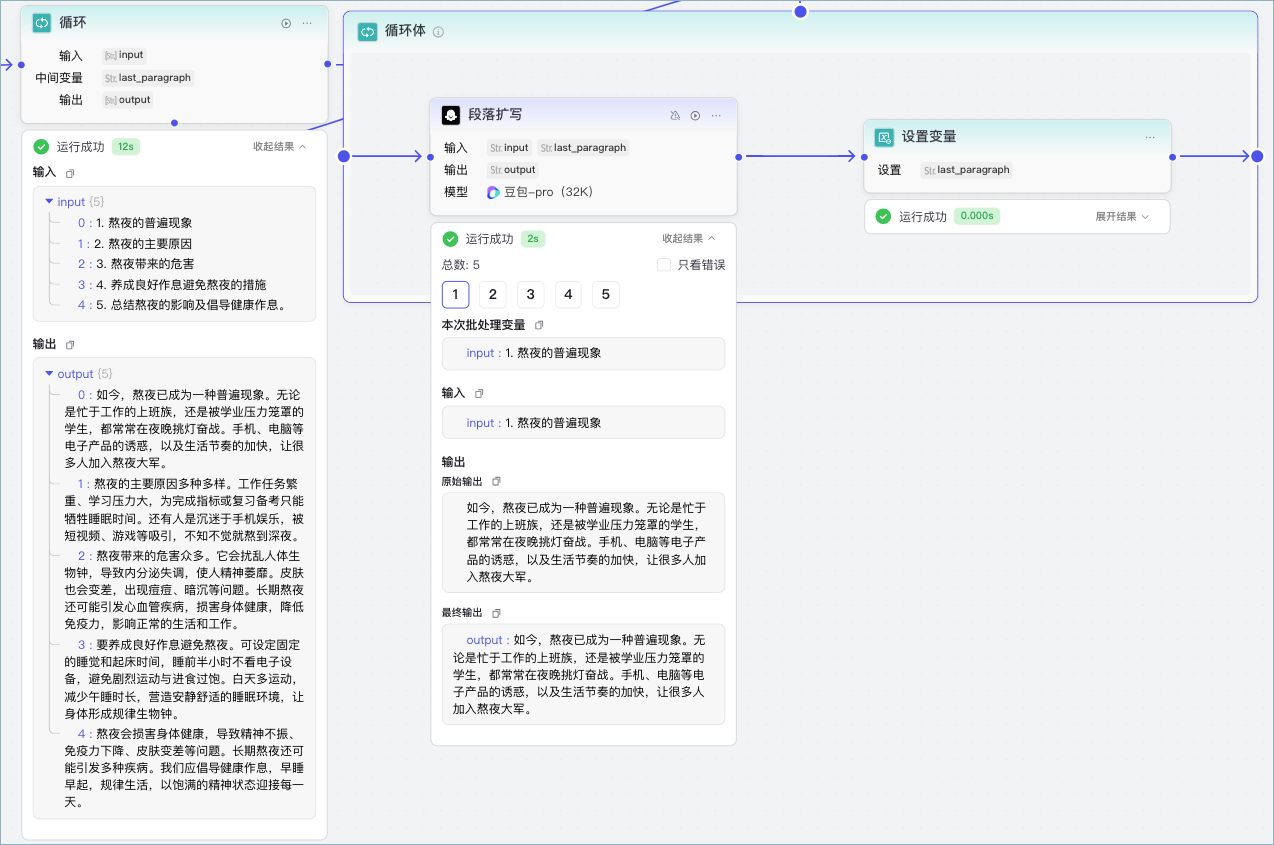
循环的引入可以提高处理效率,将复杂的任务分解为可重复执行的子任务,实现自动化流程处理
简单来说,可以从这两个方面来理解Coze中的循环:
1.对某个事物进行多次处理:例如对某篇文章进行全部论点的输出(论点会存在多个,所以处理过程存在循环)
2.对多个事物进行批处理,存在循环,为工作流节点中的批处理
在本次的智能体编辑中,我们就以上面两种情况分别给大家展示如何实现节点中的循环处理
(1)📃首先是对某个事物进行多次处理
例如对某篇文章进行全部论点的输出(论点会存在多个,所以处理过程存在循环)
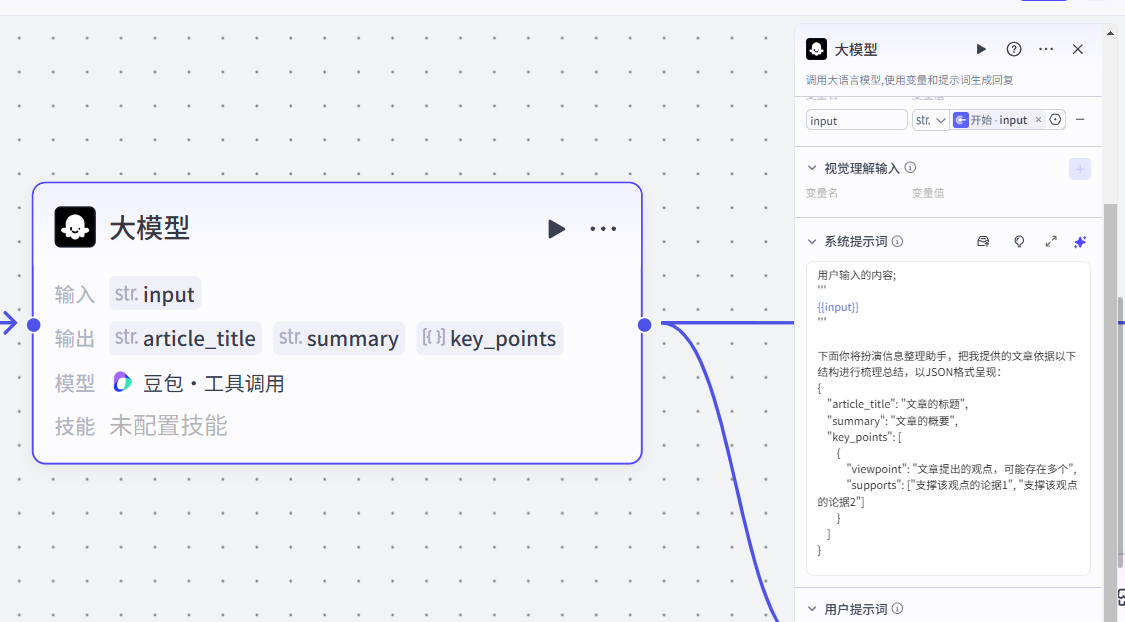
我们在处理的时候,并不需要选择大模型处理方式为批处理,而是选择单次,通过系统提示词的撰写去实现循环
在提示词的撰写中,我们定义了智能体的角色身份,并且限制了输出格式,这里就涉及到了本节的重点:Josn格式
⌨️什么是JSON格式?
JSON(JavaScript Object Notation)是一种 轻量级的数据交换格式
具有 简洁、易读、易于机器解析和生成 的特点,在大模型插件中使用JSON格式打造提示词能够提升智能体的处理效率,并且还易于我们在处理负责工作流时,准确地对某个模块的内容进行输出
在大模型插件的使用中,提示词的设计是非常重要的
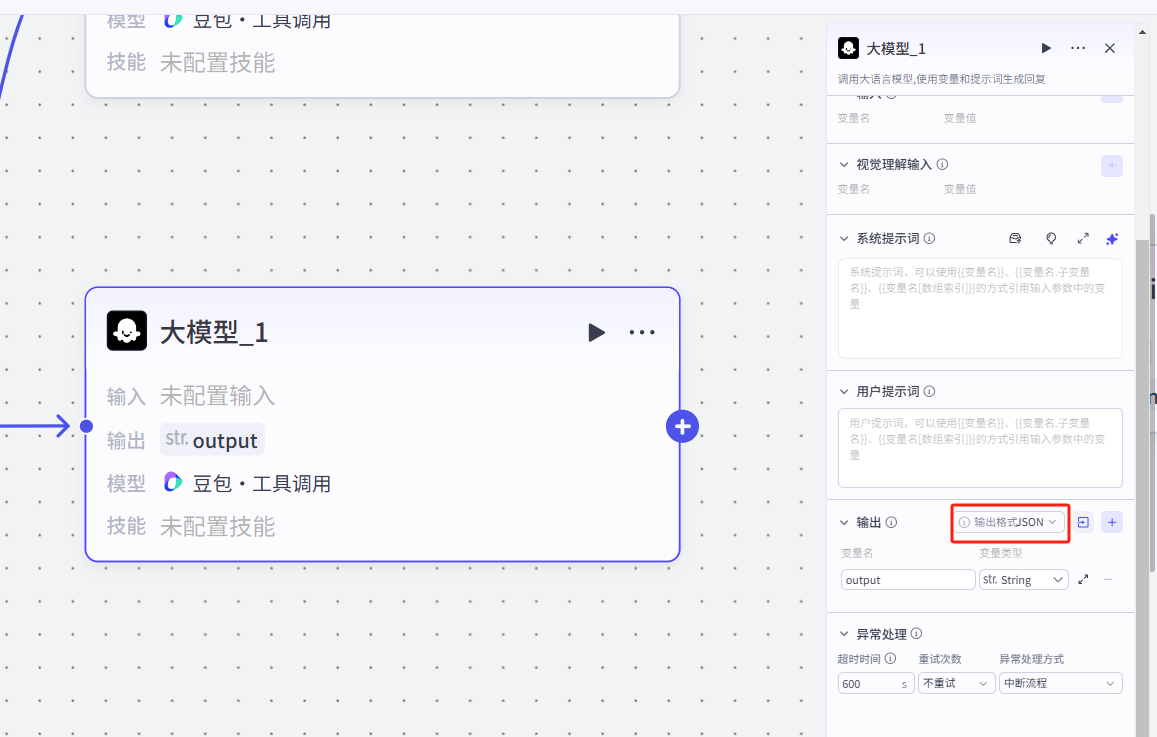
大家可以在大模型的配置面板看到一个内容,输出格式JSON
它以纯文本的形式来存储和表示数据,使用键值对的方式组织数据结构,例如:
{
"name": "Tom",
"age": 25
}这么说或许有些复杂,但大家只需要记住一点就行
Josn格式的表达方式就是:
{
"变量名":"变量值",
"变量名":"变量值",
"变量名":"变量值"
}攥写过程中,除开变量名称和变量值可以使用中文,其他字符必须使用英文
并且,所有变量和变量值的最外面需要用 {} 框起来
每一个变量写完之后,都需要使用 , 隔开,但是在最后一个变量的末尾不能够添加 ,
运用Josn格式的核心就是将文字数据用变量代替,减少工作流中的工作量
不过,这样的表达方式其实有时候也不能完全满足我们的场景需求,例如:
假设你要为家里准备一次家庭聚会,需要邀请很多亲戚,这时候就可以用 JSON 格式来记录亲戚们的信息,其中还会用到一个新的概念——数组。
每个亲戚都有名字、年龄、联系方式,而且有的亲戚可能还带着自己的孩子一起来参加聚会。这就好比每个亲戚是一个 “信息包”,而孩子的信息就像是放在这个 “信息包” 里的一个小包裹,我们可以用数组来装这些小包裹
用 JSON 格式记录就像下面这样:
[
{
"亲戚姓名": "叔叔",
"年龄": 45,
"联系方式": "136xxxx5678",
"同行孩子": ["堂弟", "堂妹"]
}
,
{
"亲戚姓名": "姑姑",
"年龄": 42,
"联系方式": "139xxxx8910",
"同行孩子": ["表哥"]},
{
"亲戚姓名": "舅舅",
"年龄": 40,
"联系方式": "133xxxx2345",
"同行孩子": []
}
]在这个例子里,最外面的
[]是一个大数组,里面包含了每个亲戚的信息。每个亲戚的信息又是用{}括起来的 “键值对” 集合。“同行孩子” 这个键对应的值就是一个数组
像叔叔带着堂弟和堂妹来,所以 “同行孩子” 数组里有 “堂弟” 和 “堂妹” 两个元素;姑姑只带了表哥,数组里就只有 “表哥” 这一个元素;舅舅没带孩子来,那 “同行孩子” 数组就是空的[]
总之,数组的核心表达方式就是使用 [] 将变量框起来,并且从0开始计数,为每个子数据添加一个数字下标分别标识它们
而在大模型插件中以JSON格式打造提示词,通俗些说就是将大模型提示词中的输出demo严格规定为JSON格式
比如我们这样撰写大模型的提示词:
用户输入的内容;
'''
{{input}}
'''
下面你将扮演信息整理助手,把我提供的文章依据以下结构进行梳理总结,以JSON格式呈现:
{
"article_title": "文章的标题",
"summary": "文章的概要",
"key_points": [
{
"viewpoint": "文章提出的观点,可能存在多个",
"supports": ["支撑该观点的论据1", "支撑该观点的论据2"]
}
]
}
需要注意的是,想要实现多格式的JSON格式输出,还需要配置一下大模型的输出部分
、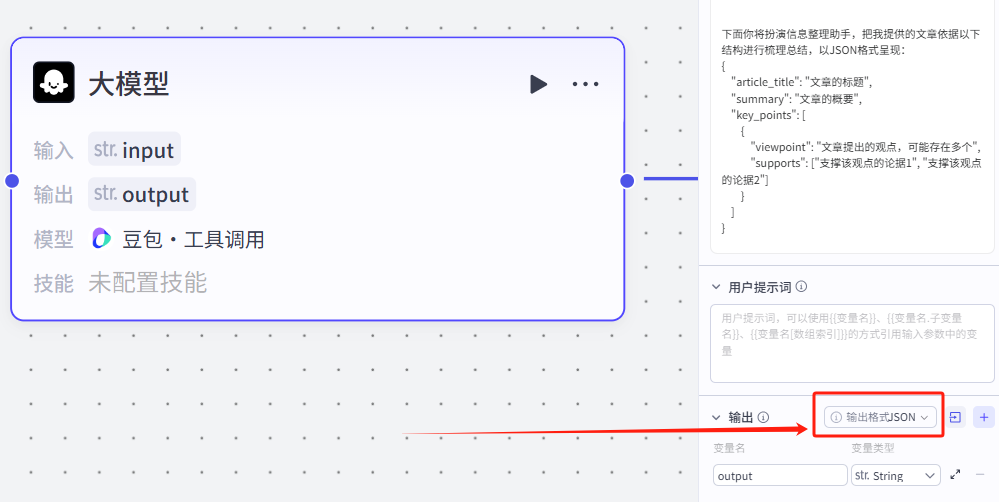
点击输出格式JSON旁边的按钮,可以导入JSON格式,直接一键写好我们的输出
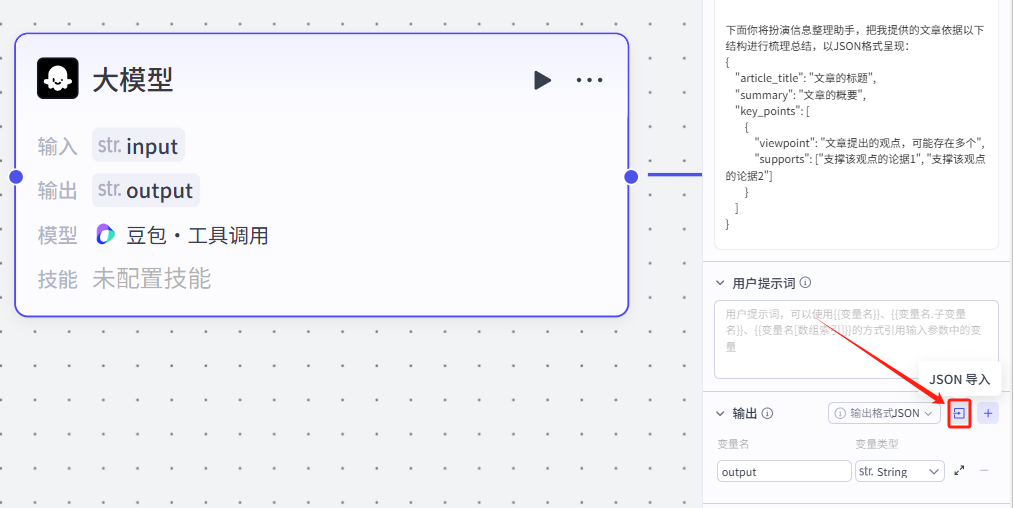
这里的输出模板需要我们先按照想要的JSON格式写好一个样式,
{
"article_title": "平凡,亦有精彩可期",
"summary": "阐述了每个人虽平凡却能活出精彩人生,以小草、清洁工为例说明平凡事物和职业的不平凡之处,还列举雷锋、李素丽等平凡人成就不凡的例子,强调平凡人也能有精彩人生",
"key_points": [
{
"viewpoint": "平凡的小草有不平凡之处",
"supports": [
"小草在公园空地、房屋墙角、垃圾堆旁等随处可见,形态多样",
"小草能让小朋友摔倒不受伤、为公园增添生机、使空气更清新,且默默奉献、任人踩踏毫无怨言",
"小草具有坚韧顽强的品质,如白居易诗‘野火烧不尽,春风吹又生’所体现"
]
},
{
"viewpoint": "平凡的清洁工有不平凡贡献",
"supports": [
"清洁工在街道上随处可见,穿着显眼橙色工作服,拿着大竹扫帚,推着铁质垃圾车,涵盖不同性别和年龄人群",
"清洁工减少了因垃圾在马路上引发的意外,能让肮脏街道变得一尘不染,使城市干净整洁",
"很多人看不起清洁工,但没有他们城市将垃圾遍地,而他们依旧埋头劳作"
]
},
{
"viewpoint": "平凡人能成就不凡",
"supports": [
"雷锋是平凡战士,却是不平凡的‘螺丝钉’",
"李素丽是平凡公共汽车售票员,却成为劳动模范"
]
},
{
"viewpoint": "平凡人可活出精彩人生",
"supports": [
"我们每个人都是平凡的,但都能活出精彩人生"
]
}
]
} 粘贴好后,选择右上角的按钮
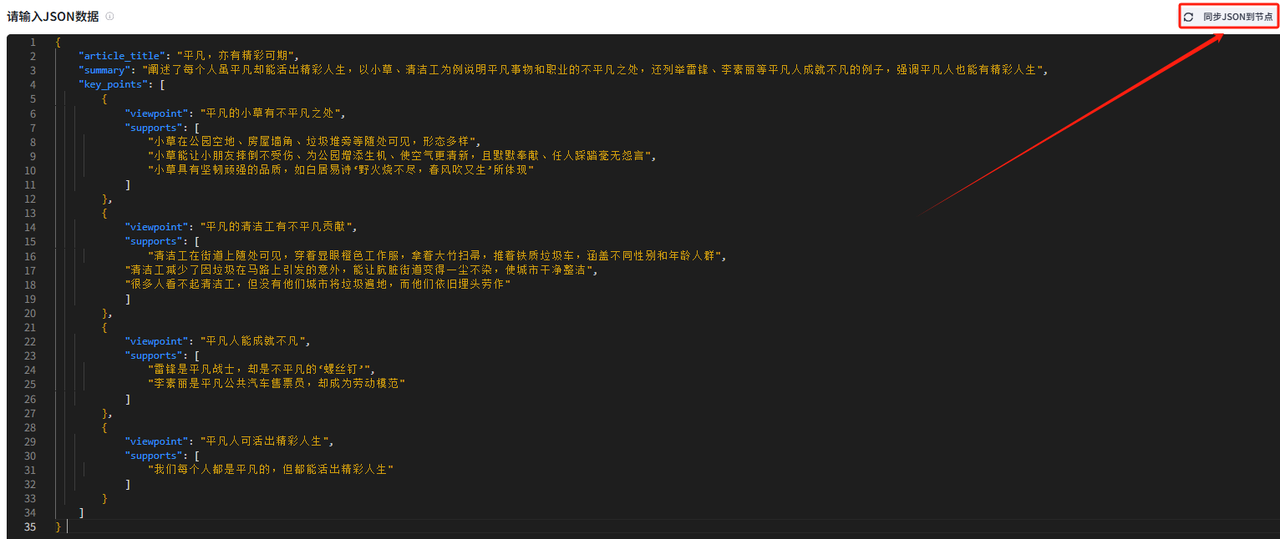
然后检查一下我们输出节点的变量,确认导入是否正确
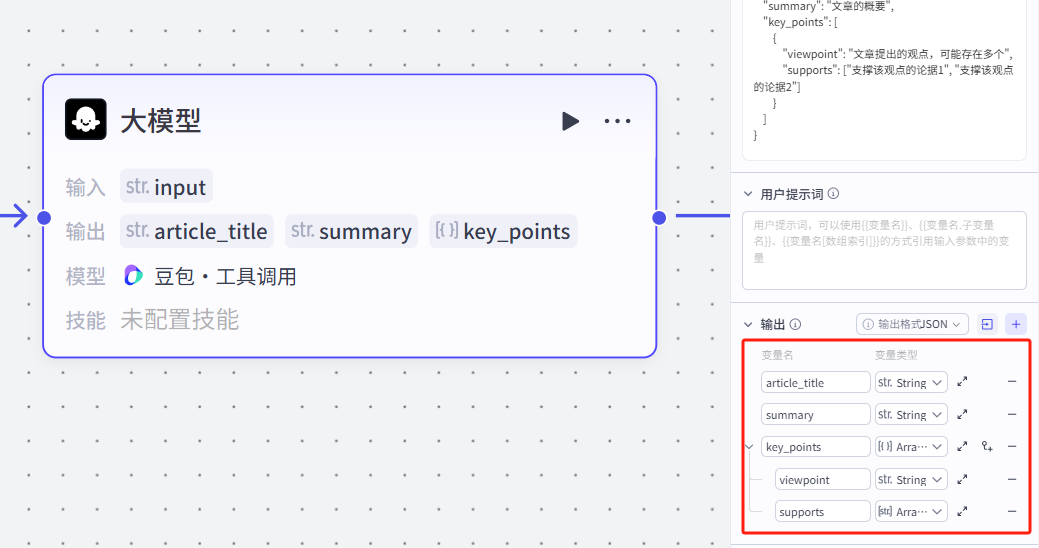
我们再定义一下结束节点:
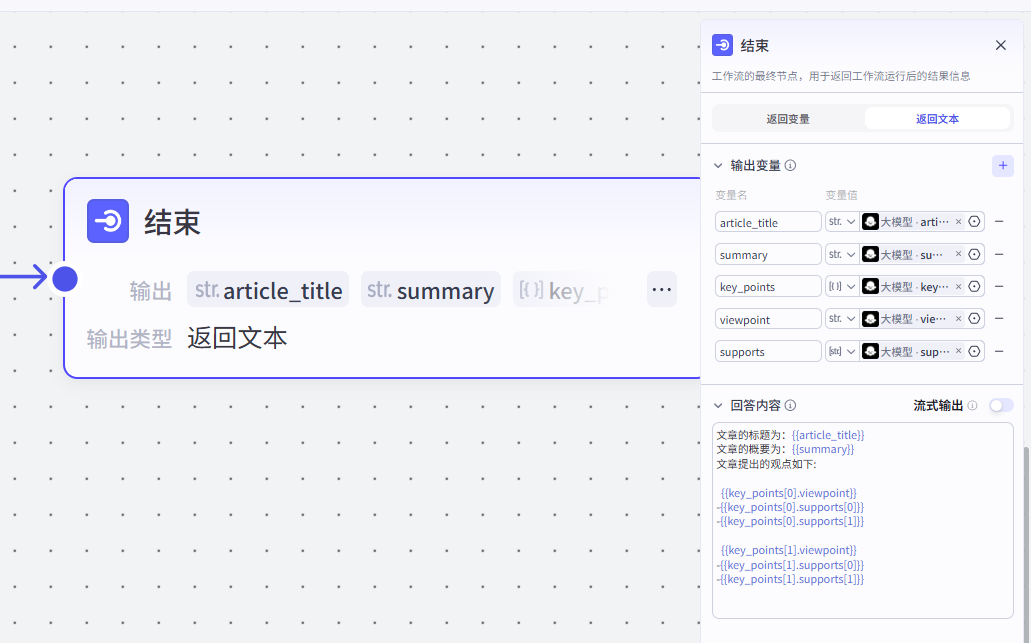
给大家参考一下我们回答内容,因为用到了一个嵌套的数组格式:
文章的标题为:{{article_title}}
文章的概要为:{{summary}}
文章提出的观点如下:
{{key_points[0].viewpoint}}
-{{key_points[0].supports[0]}}
-{{key_points[0].supports[1]}}
{{key_points[1].viewpoint}}
-{{key_points[1].supports[0]}}
-{{key_points[1].supports[1]}}再展示一下在智能体实例运用中的情况,配置一个简单的工作流查看下应用效果:

输入一篇文章进行测试
可以看到运行成功
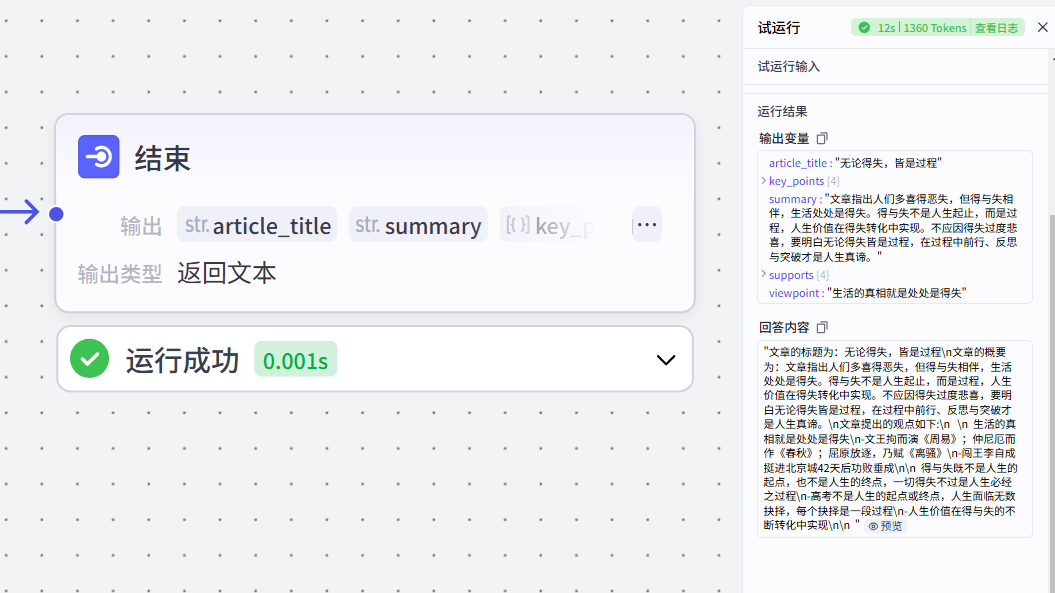
但是出现了一个问题,结束节点只输出了我们定义的那几个数组格式,没有输出完整的大模型处理内容,这个时候就涉及到第二个内容了——对多个事物进行批处理
(2)🗂️对多个事物进行批处理(处理数组变量)
智能体中的工作流节点,拥有单次和批处理(循环)的处理方式
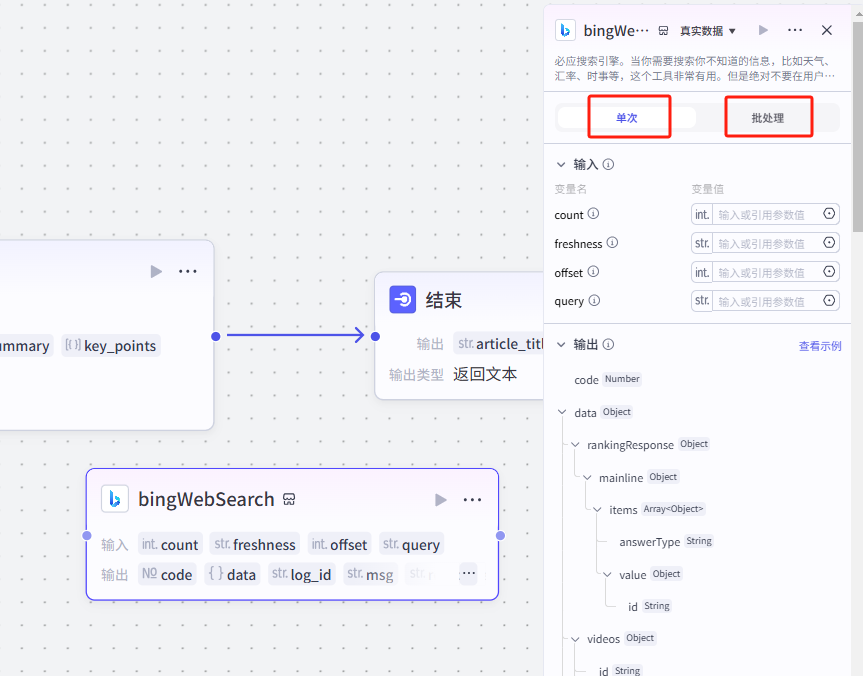
首先需要注意的是,批处理节点只接收数组格式,因为数据如果不是数组格式,是无法完成循环的

包括工作流节点中的循环节点,它也只支持数组循环
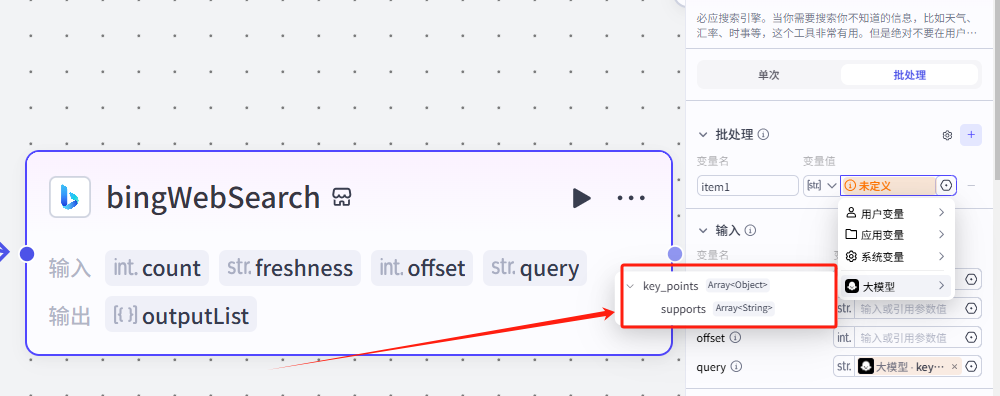
给大家展示一下批处理节点bingWebSearch具体的配置步骤
|
步骤说明
|
|
|---|---|
|
1.定义一下需要批处理的变量,这里可以看到我们能够选择两个变量,因为它们两个都是数组
 |
|
|
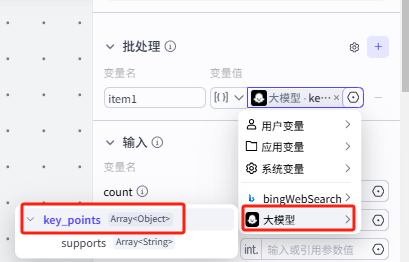
2.这里的循环变量选择 key_points(论据),方便我们在下面的设置可以进一步选择对象进行搜索循环
 |
|
|
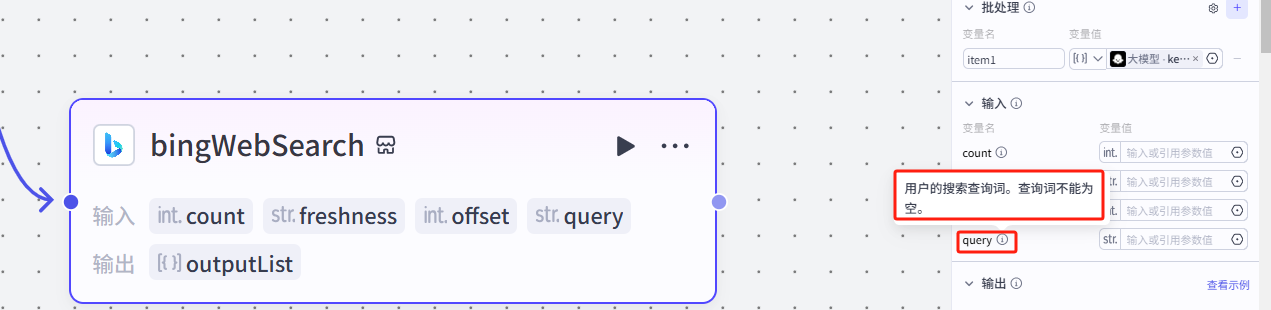
3.接下来可以看到输入这里还有一个变量,搜索查询词 —— query
 |
|
|
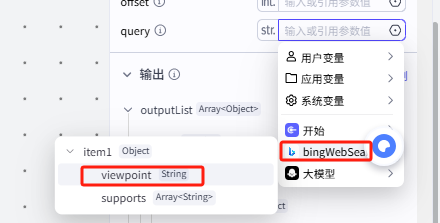
4.这个部分需要选择我们的循环节点,也就是批处理节点bingWebSearch
然后选择节点中的批处理参数item1下的viewpoint
 |
|
|
5.然后我们更改一下工作流的结束节点,再测试一下
可以看到我们在选择输出变量的时候,bingWebSearch下的内容很多
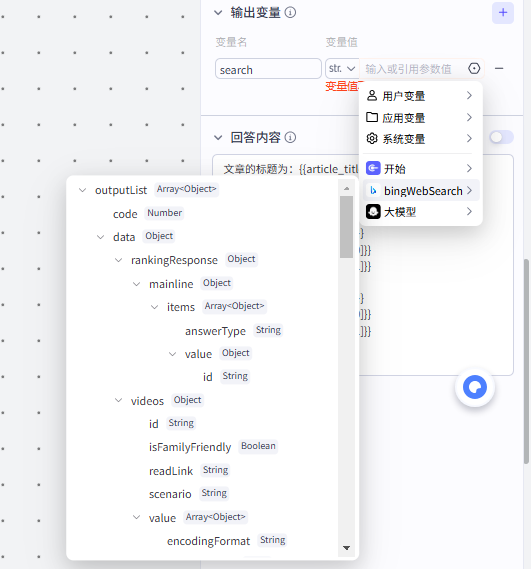 小TIPS:这里顺便教一下大家面对这种情况,该如何去判断我们需要输出的变量
|
|
|
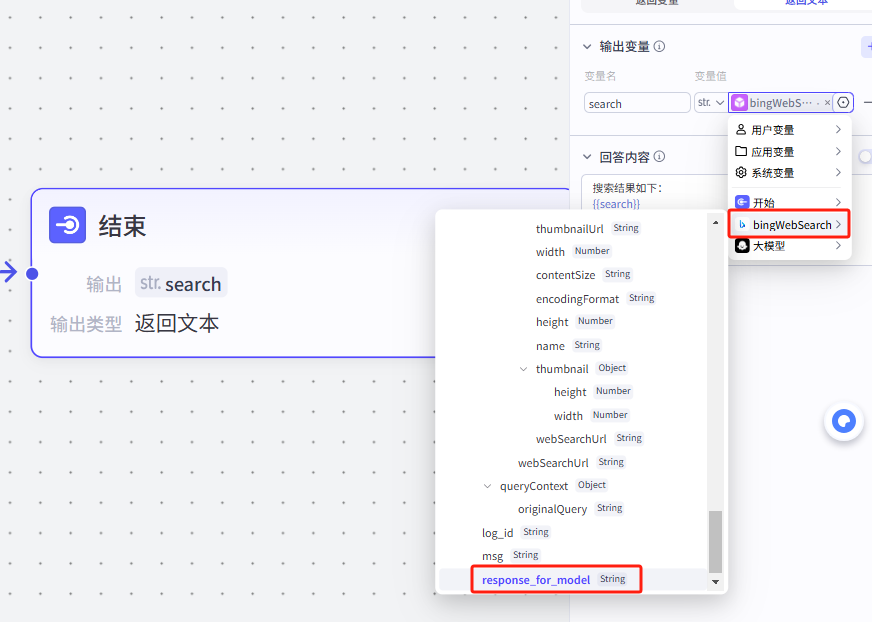
6.选择好输出变量
 |
|
|
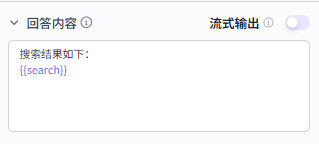
7.最后再定义一下输出
 |
接下来测试下工作流

测试流程如下
|
测试步骤
|
测试说明
|
|---|---|
|
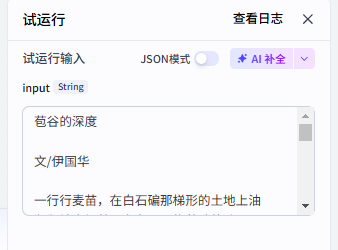
输入测试样例:
|
 |
|
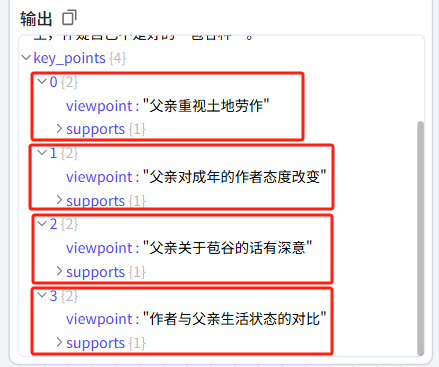
筛查大模型节点
 |
可以看到大模型输出的key_points有四个
我们循环处理的目的是对每一个viewpoint进行搜索,接下来查看下循环搜索节点是否完成了我们的需求
 |
|
筛查循环处理节点
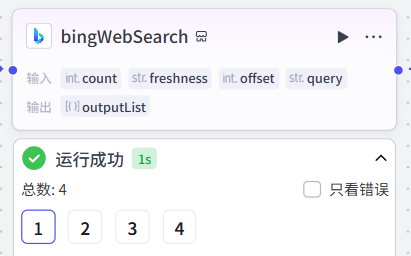 |
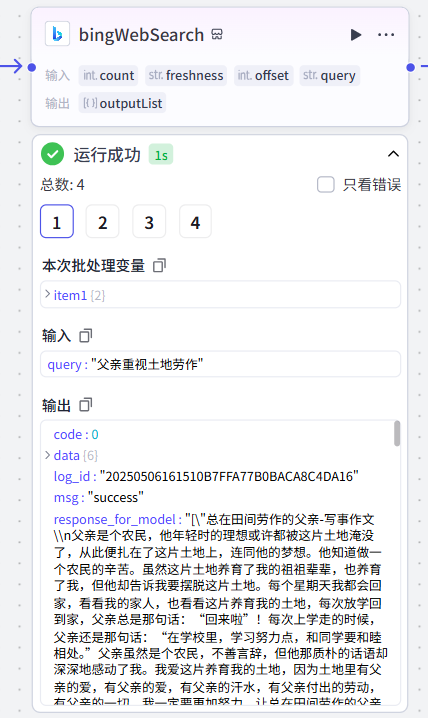
key_points[0]运行成功
 |
|
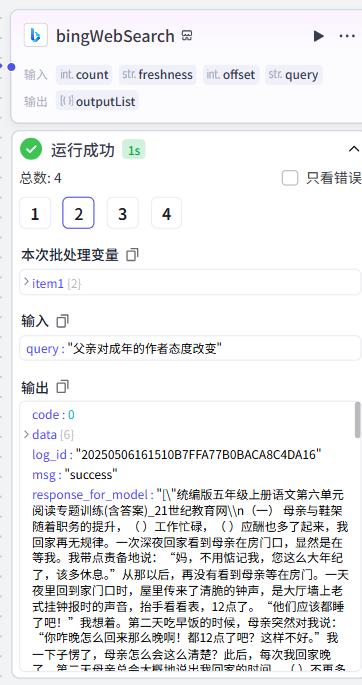
key_points[1]运行成功
 |
|
|
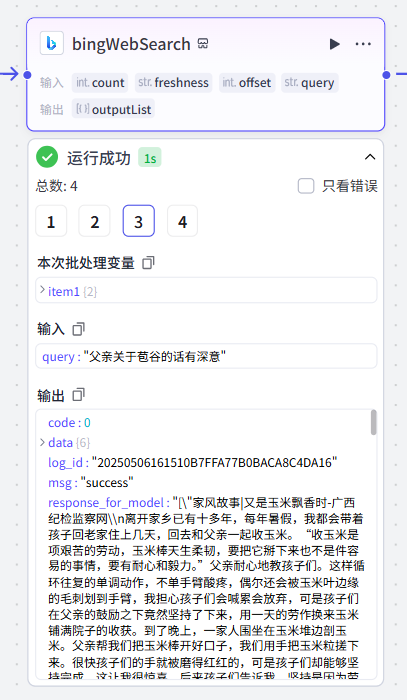
key_points[2]运行成功
 |
|
|
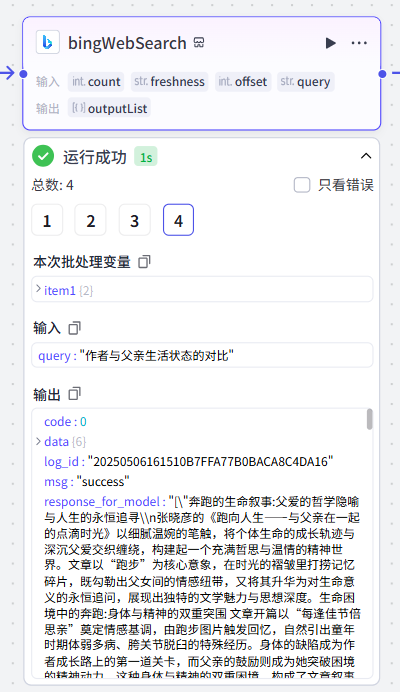
key_points[3]运行成功
 |
|
|
筛查结束节点
 |
结束节点运行成功
按照我们的指定变量进行了输出
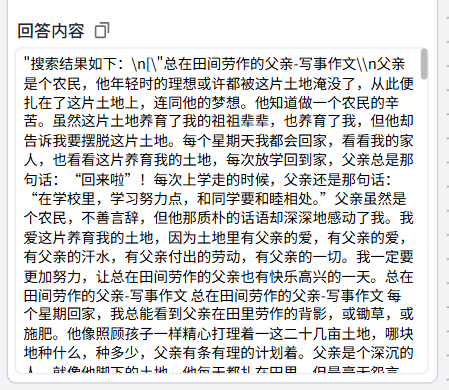 |
由此可见,只要我们工作流中前方输出的变量为数组,就可以用批处理的方式去设计循环,来去执行这样的任务
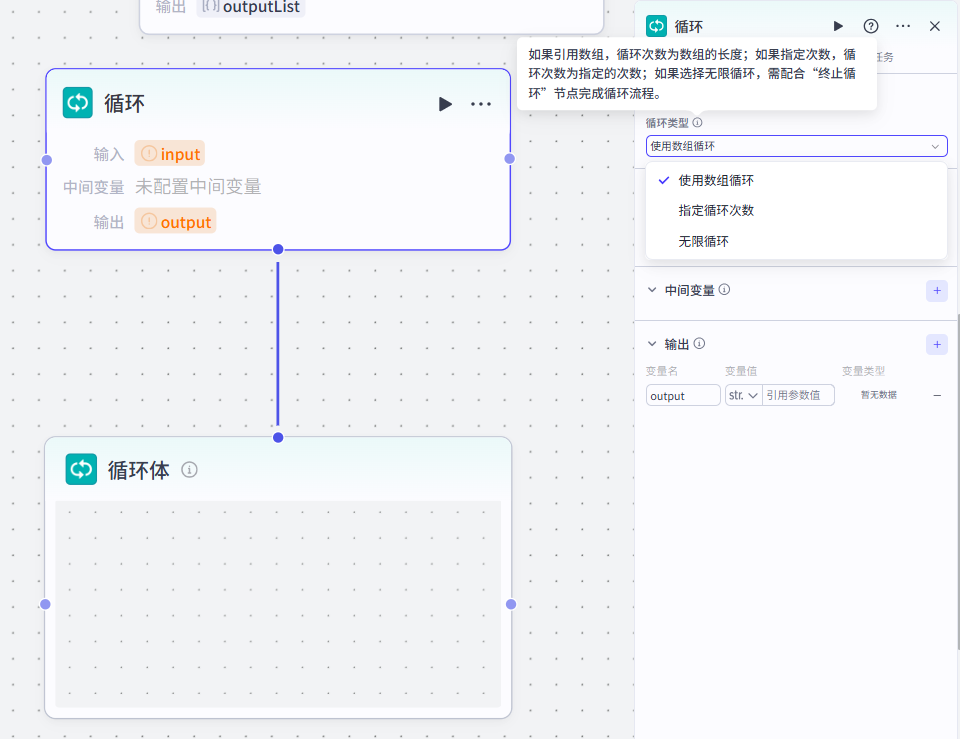
前面有提到过,除了插件节点中配置处的批处理,工作流节点也是有一个循环工作流节点的
那么如果是使用这个节点来做循环,该怎么配置呢?
首先添加循环节点,将它和前面的大模型节点链接起来
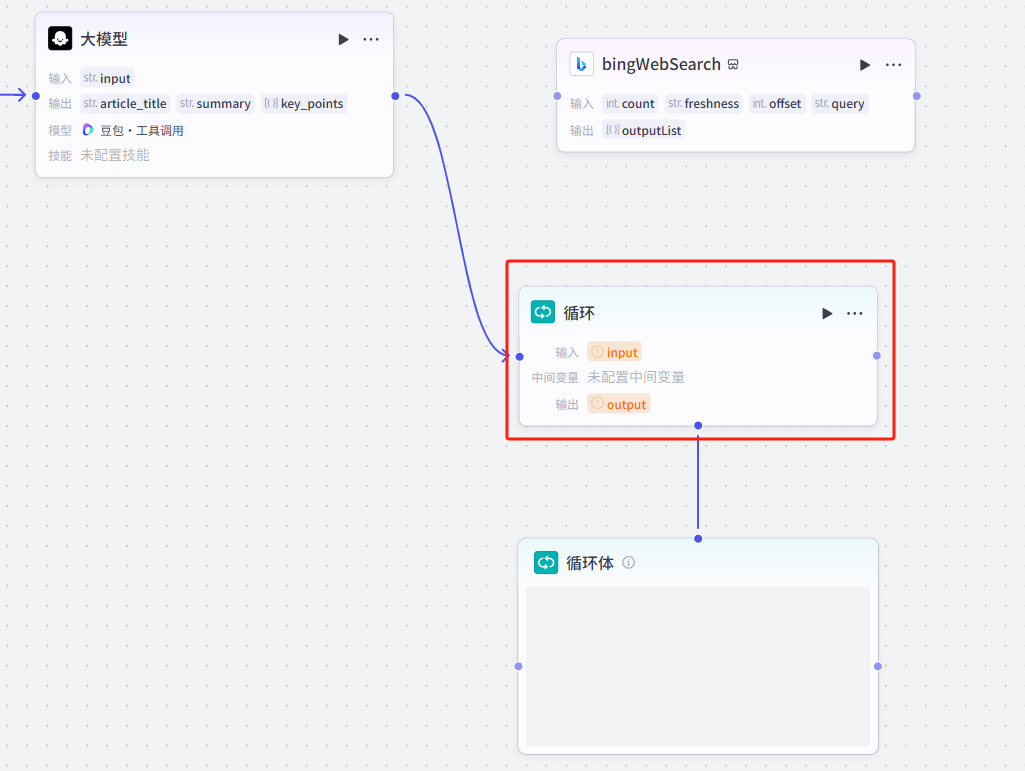
先配置循环部分
|
配置步骤
|
配置说明
|
配置示例
|
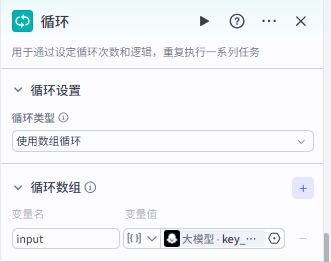
|
配置输入
|
还是选择key_points
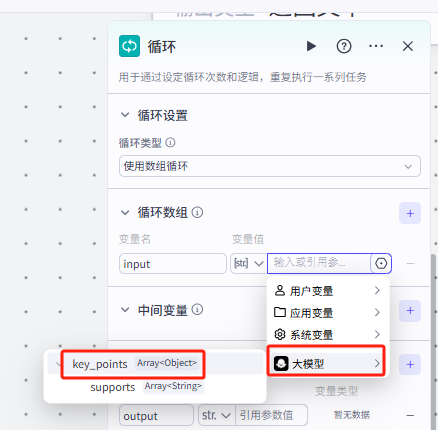 |
 |
|
中间变量
 |
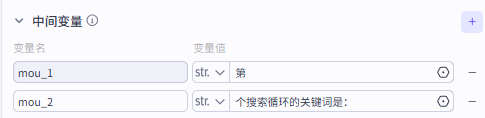
中间变量是一个可以在循环中多次显示的变量,它可以使用变量,也可以直接赋值
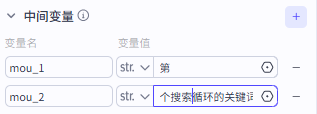
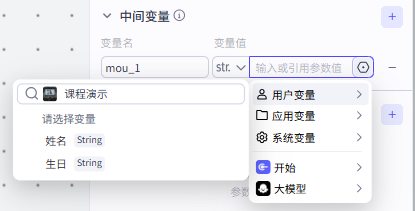 我们这里直接采用赋值的方式设置了两个中间变量
 |
 |
然后再设置循环体部分:
|
配置部分
|
配置说明
|
配置示例
|
|
循环本体设置
 |
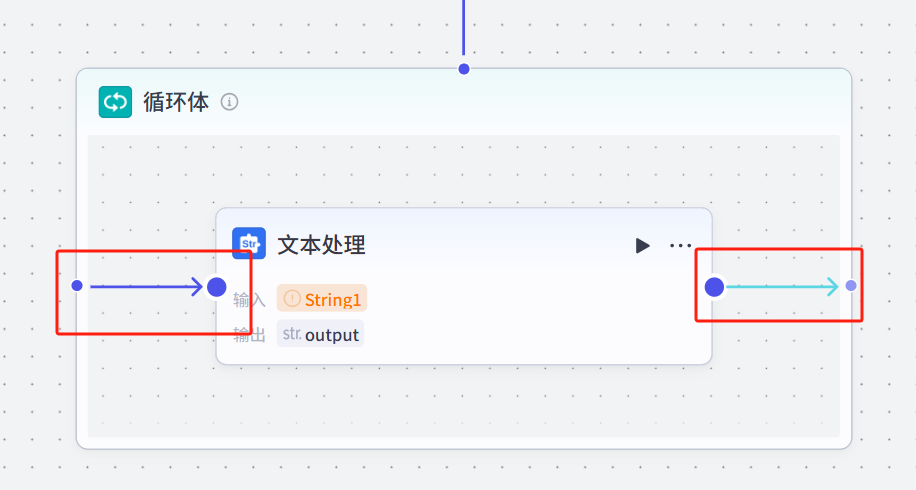
循环体内是需要添加一个节点作为循环本体的,相当于循环节点属于一个嵌套化的节点,是用于实现某个工作流节点的循环,当然如果你想要添加多个工作流节点做循环,也是可以的
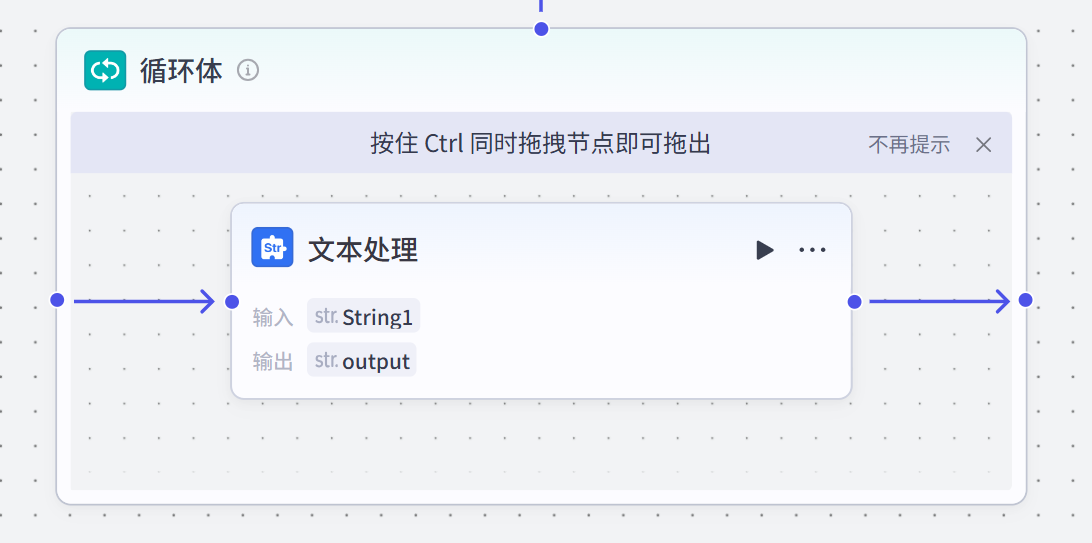
我们这里添加一个文本处理节点作为循环体,添加成功之后,记得将循环本体和循环体的起始结束节点链接起来
 |
 |
|
配置循环体——配置文本处理节点
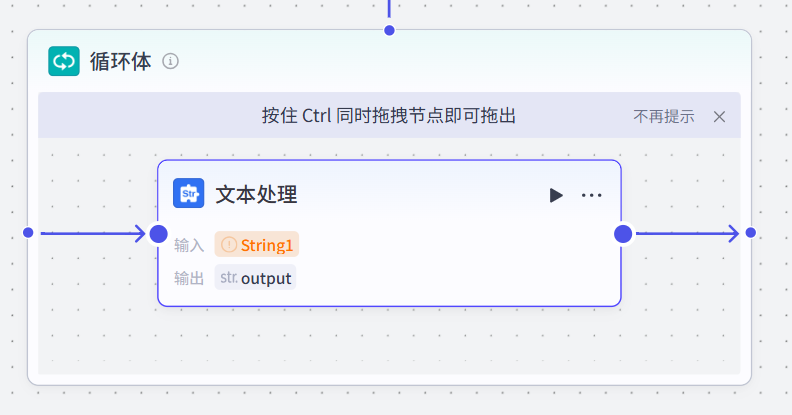 |
接下来我们开始配置循环体,也就是配置文本处理节点
我们最后需要实现的结果是进行论点的输出,实现输出:第X个搜索关键词是Y
那么接下来我们添加一下字符串变量,进行拼接,实现这样的输出,依次添加四个字符串,再拼接
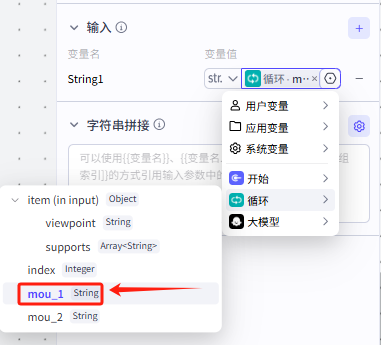 记得需要输出的关键词为循环节点的viewpoint
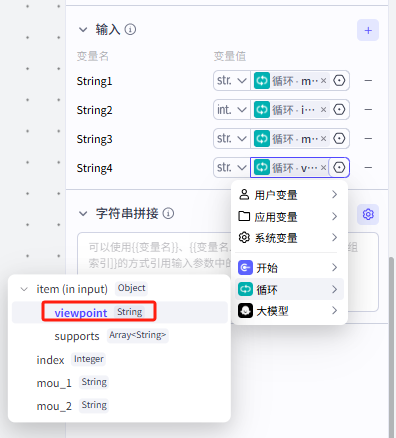 设置好之后就是这样:
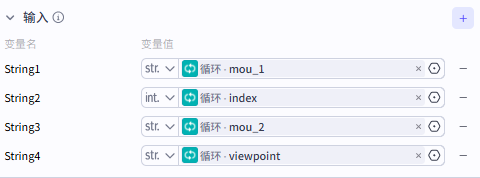 然后再拼接一下字符串即可:
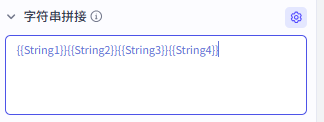 |
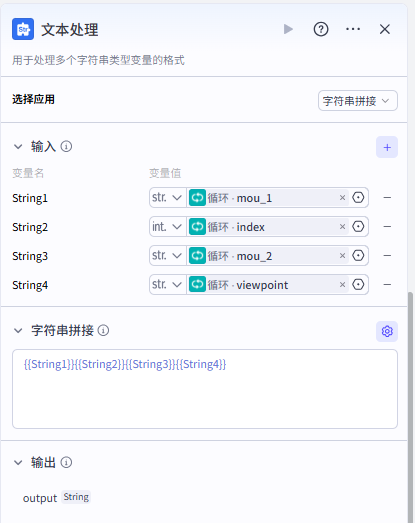 |
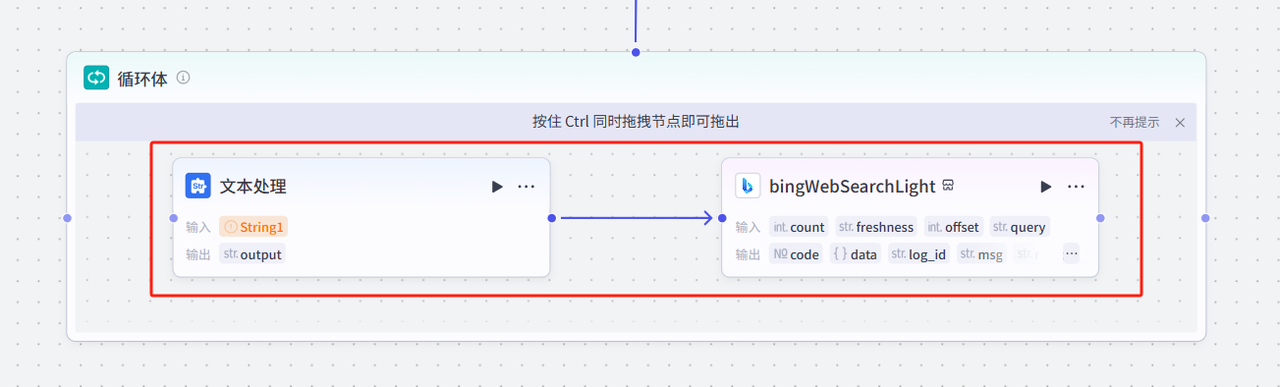
接下来我们看一下这样配置之后的工作流会输出什么:
将循环节点和结束节点链接起来,然后删除结束节点的输出,因为文本处理部分会自动进行输出
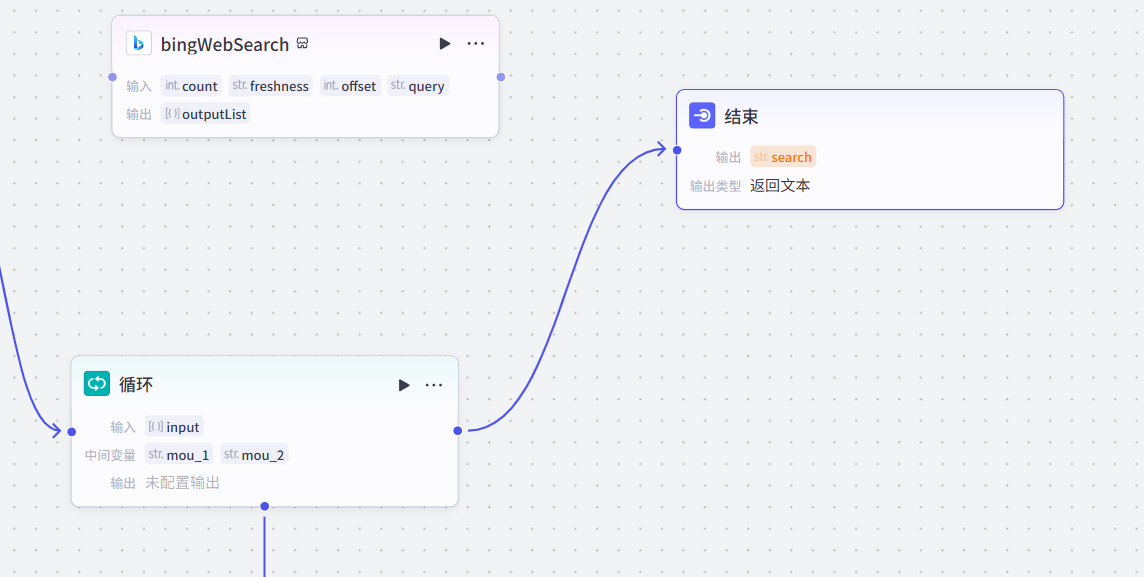
还是使用之前的测试样例进行测试,点击试运行
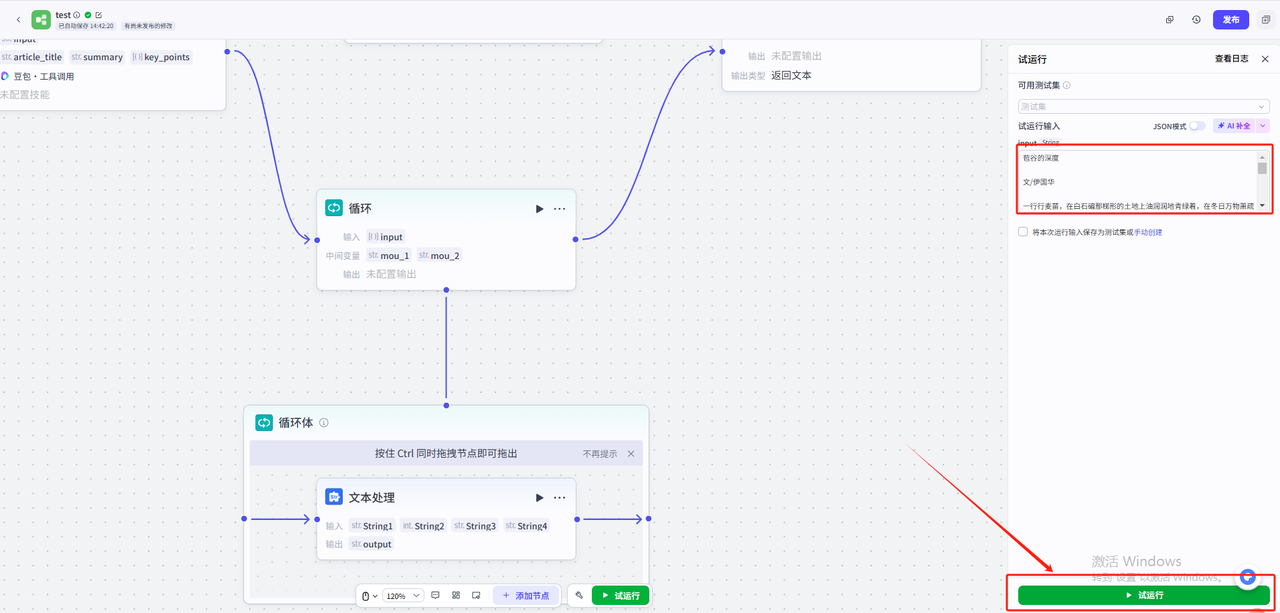
可以看到循环体依次输出了我们的循环搜索关键词
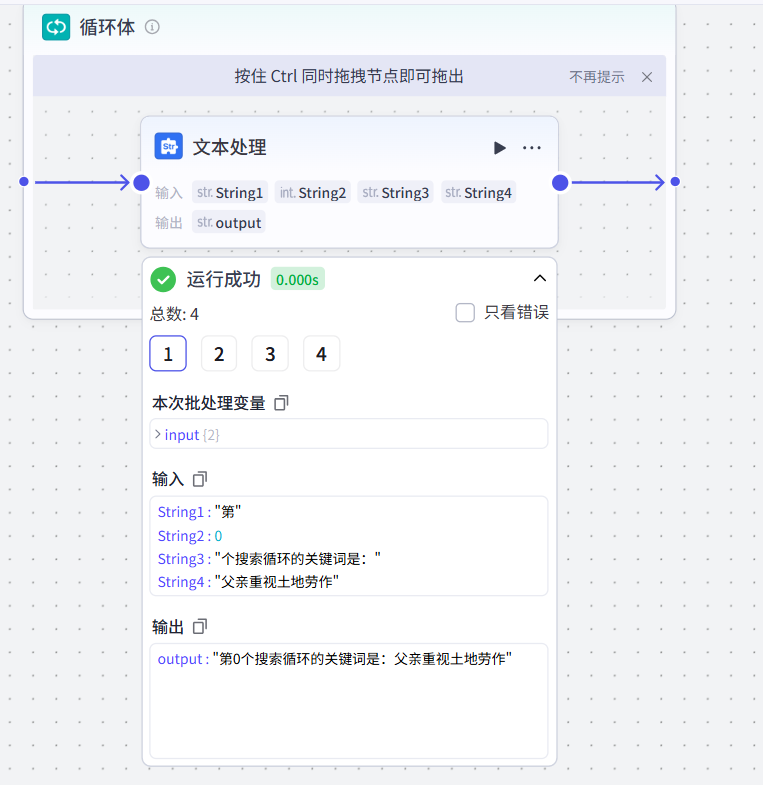
循环的文本处理节点适用于我们在工作流中输出了大量的不同的数据,想要在后面进行数据的拼接合并,那么如果使用大模型的批处理结点的话,耗时是非常长的,因为大模型要一次次进行搜索和检索,再完成拼接和输出,但文本处理节点不需要搜索,所以运行速度是很快的,适用于我们在处理这种情况时,优化用户的体验,减少工作流的运行时间
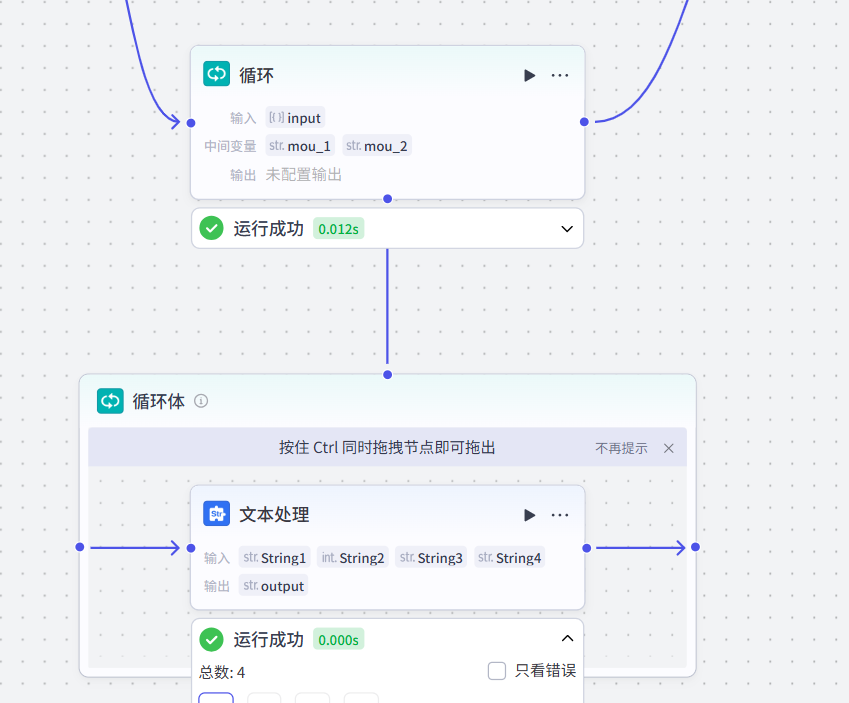
前面也提到过,循环体内也可以进行嵌套,添加多个工作流节点,进行进一步的优化工作流节点中的复杂性任务