通俗些说,大模型的底层原理就是通过对用户输入的文本进行加工、重组,散发性生成它们认为的用户希望得到的答案,也就是:
“提示词 + 生成答案” 运行机制
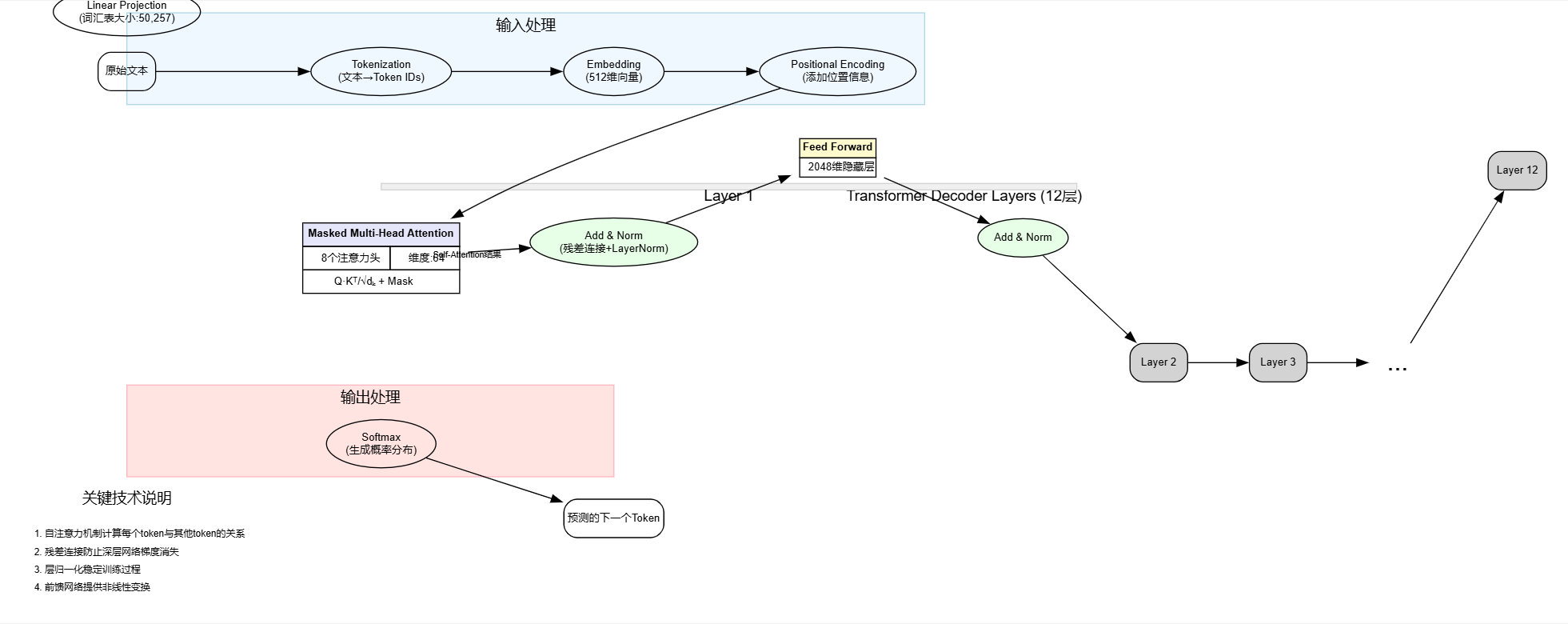
想象你在教GPT玩‘词语接龙——
你输入一句话,比如‘今天天气真’,然后让GPT猜下一个词
首先,GPT会把这句话拆成小碎片(Token),比如‘今天’、‘天气’、‘真’,然后给每个词分配一个‘数字密码’(Embedding),这样计算机才能理解

接下来,GPT会像人类一样思考这些词之间的关系
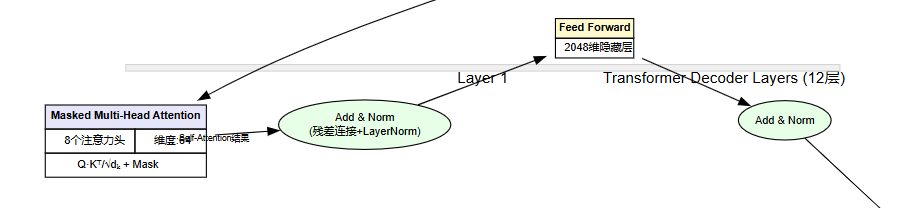
它有一个超能力:同时看所有词,并决定哪些词更重要。比如:
-
‘天气’和‘真’关系更紧密(可能接‘好’或‘差’)
-
‘今天’和‘天气’是一组(说明在聊天气) 这个超能力叫自注意力,就像你读书时会用荧光笔标出重点词一样。
GPT不止看一遍,它会反复‘琢磨’很多遍(12层甚至更多)
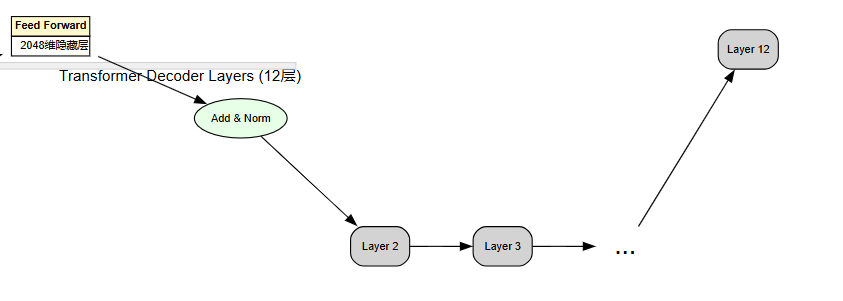
每一层都会更深入理解句子的含义:
-
第一层可能发现‘天气’是个话题
-
中间层明白‘真’后面通常接形容词
-
深层会结合常识,知道‘天气真…’更可能是‘好’而不是‘香蕉’
最后,GPT把所有‘思考结果’汇总,从几万个词里挑一个最合适的接在后面

比如‘今天天气真→好’,这就是它玩‘词语接龙’的方式
简单点说,它的工作流程可以这样理解:
-
拆词加密:把文字变成计算机能算的数字
-
找词关系:同时分析所有词之间的联系(自注意力)
-
层层深入:像剥洋葱一样,越往里理解越聪明
-
猜下一个词:基于所有分析,选概率最高的词接龙

