1.🗄️知识库的按需调用
当智能体在运行时,除了用户对话体验,用户的等待时长也是相当重要的
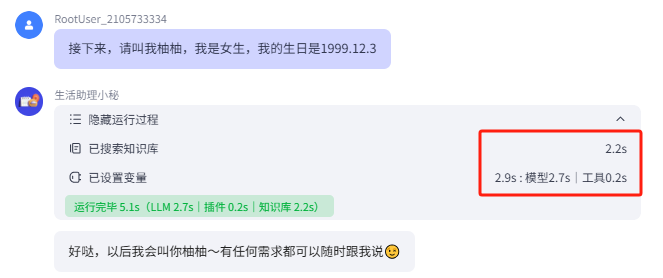
我们点开上一轮的对话可以发现,每个步骤都有详细的时间,如果用户等待智能体运行的时间过长,会降低体验感,所以限定知识库的按需调用是非常有必要的
其实这部分我们在前面的提示词部分已经给大家做了,就是给小秘设定不同的人设回复逻辑,当用户画像篇年轻化的时候,小秘会在回复中携带热梗,并且我们限定热梗只能来源于上传的热梗知识库

这里给大家展示一下,商务模式下的小秘是不会调用热梗知识库的
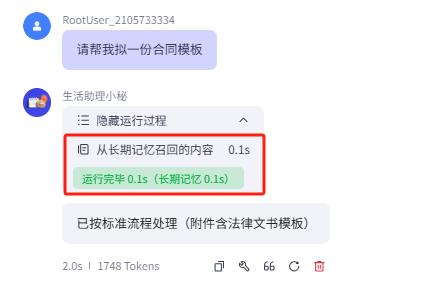
由于我们这部分的教程还比较基础,没有更深入的对知识库进行限定,所以大家只需要跟我们一样,在提示词中进行调用限定即可
多场景下的知识库精准调用
除了前面提到的根据用户画像设定不同人设回复逻辑来限定知识库调用
我们还可以在更多场景下实现知识库的精准调用
例如,在不同的业务场景中,智能体需要调用不同的知识库
假设我们有一个电商平台的智能客服工作流,当用户咨询商品信息时,智能体需要调用商品知识库;当用户咨询物流信息时,智能体需要调用物流知识库
我们可以在工作流中添加一个场景判断节点,根据用户的输入判断当前的业务场景,然后根据场景来选择调用相应的知识库
如果用户输入包含商品关键词(如产品名称、型号等):
- 调用商品知识库
如果用户输入包含物流关键词(如快递单号、配送时间等):
- 调用物流知识库这样,智能体就可以在不同的业务场景下快速准确地调用所需的知识库,提高回复的效率和准确性
知识库与其他功能的结合调用
除了单独调用知识库,我们还可以将知识库与其他功能结合起来使用
例如,我们可以将知识库与大模型结合,让大模型根据知识库的内容进行推理和生成回复
在智能客服工作流中,我们可以先让大模型根据用户的输入从知识库中筛选出相关的信息,然后再对这些信息进行处理和生成回复。这样,大模型就可以利用知识库中的知识,给出更加准确和详细的回复。
我们还可以将知识库与变量结合使用
例如,我们有一个变量“用户等级”,根据用户等级的不同,智能体可以调用不同级别的知识库
如果用户等级为高级会员,智能体可以调用高级会员专属的知识库,提供更优质的服务
2.🤖不同大模型的选择与使用
除了这些优化方向,大模型的选择与使用也是很重要的
因为不同的大模型在不同的领域其实功能等级不尽相同,有些大模型擅长处理长文本,有些大模型擅长处理图片等
这里整理了一个表格帮助大家去了解不同大模型的特点和适用领域:
|
模型名称
|
特点
|
适用领域
|
不支持内容
|
|---|---|---|---|
|
豆包
|
功能全面,具备多模态能力,支持文本、图像、语音等处理;实时数据处理能力强,可联网获取最新数据;语音交互流畅,识别精准度高且支持多轮对话
|
自然语言处理领域广泛适用,如长文本解析、日常对话交流、知识问答、文案创作 、智能客服、日常语音助手等场景
|
违反法律法规、违背道德伦理的内容,如宣扬恐怖主义、色情低俗等;在需要高度创新思维和情感渲染的文本生成中,风格多样性可能不足
|
|
百川
|
在文本生成方面优势显著,能快速产出高质量文案
|
创意写作、商业文案撰写等文案创作领域
|
极度复杂、高度专业且包含大量隐晦行业“黑话”的内容,如特定超小众科研领域用独特代码语言写的专业报告解读;违法违规、危害国家安全等不良内容
|
|
通义千问
|
中文处理能力较强,支持多轮对话;知识覆盖范围广泛;交互流畅,用户体验较好
|
中文用户的知识问答、文案创作;办公场景(提供实用办公技巧、文档处理建议 )、生活常识领域(对生活问题咨询给出合理回答)
|
生成极度前沿、刚萌芽还未公开化的新兴科技理论详细内容;传播违法犯罪、虚假不实等有害信息
|
|
DeepSeek
|
在处理需要强大语义理解能力的任务上优势明显,如阅读理解、信息抽取;逻辑推理与代码生成能力出色,适合数学解题、代码生成等场景 ;具备低成本与开源优势,支持本地化部署
|
长文本语义理解和关键信息提取工作;开发者和学术研究场景;对隐私和数据安全要求较高的场景 ;问答、文本生成、数据分析等任务
|
需要生成特别“脑洞大开”、毫无逻辑关联却要强行创意融合的内容;生成可能造成伤害或误导的有害内容;目前缺乏图像、语音等多模态能力
|
|
Minimax
|
擅长对话交互场景,能与用户进行自然流畅的对话交流
|
聊天、智能客服等应用场景
|
生成极其晦涩、冷僻,几乎没人使用的古代语言语法结构的文本内容;违反学术规范、法律准则的相关内容;在严谨的学术内容生成以及专业法律条文解读等领域,准确性和深入性可能不足
|
|
智谱
|
中文处理能力优秀;在知识图谱构建以及基于知识图谱的推理方面表现出色,提供知识图谱和结构化输出
|
中文用户的知识问答、内容创作;需要逻辑推理和知识关联的任务,如解答复杂学术问题、分析事件之间的逻辑关系等
|
生成特别注重情感泛滥、无节制夸张表达且毫无理性逻辑可言的内容;破坏学术诚信、误导公众的信息;在一些对语言趣味性和创意性表达要求较高的场景中,表现可能相对不突出
|
|
Moonshot
|
在图像相关的文本描述生成方面具有独特亮点,能结合图像进行故事创作、对图像内容进行详细文字解读
|
适合与图像相关的文本创作和解读场景
|
纯粹关于超级复杂、无图形关联的高等数学算法推理,并且要详细到极致的文本内容;违法违规、违背公序良俗的内容;在单纯的纯文本逻辑推理以及复杂的算法问题解决等方面能力相对有限
|
表格所示信息是2025.4.8整理收集出来的,各模型的能力处于不断迭代提升的动态过程中
在实际应用时,需要根据具体的需求和实际情况,综合考量并灵活选择合适的模型,同时要明确各模型不支持的内容范围,确保使用的合理性和合法性
3.✏️模型对比调试
并且在实际调试过程中,Coze也是支持我们同时对两个不同的模型进行测试的
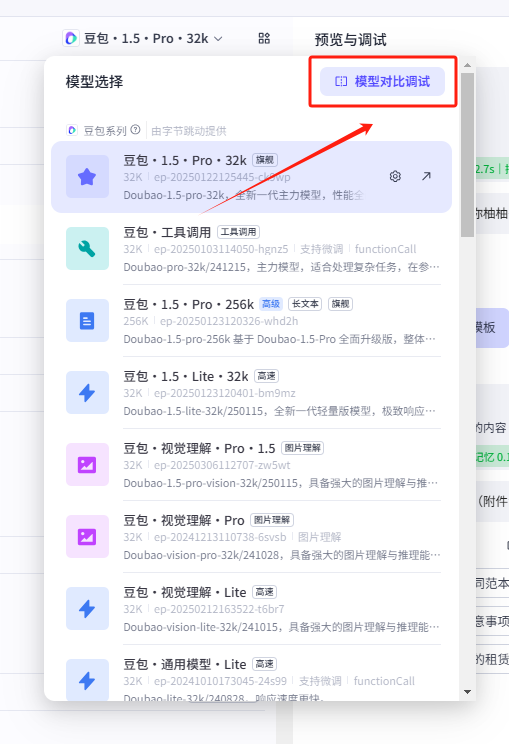
点击之后,就会进入双模型对比调试界面,能够让我们非常直观的感受到两个模型的对话适配程度:
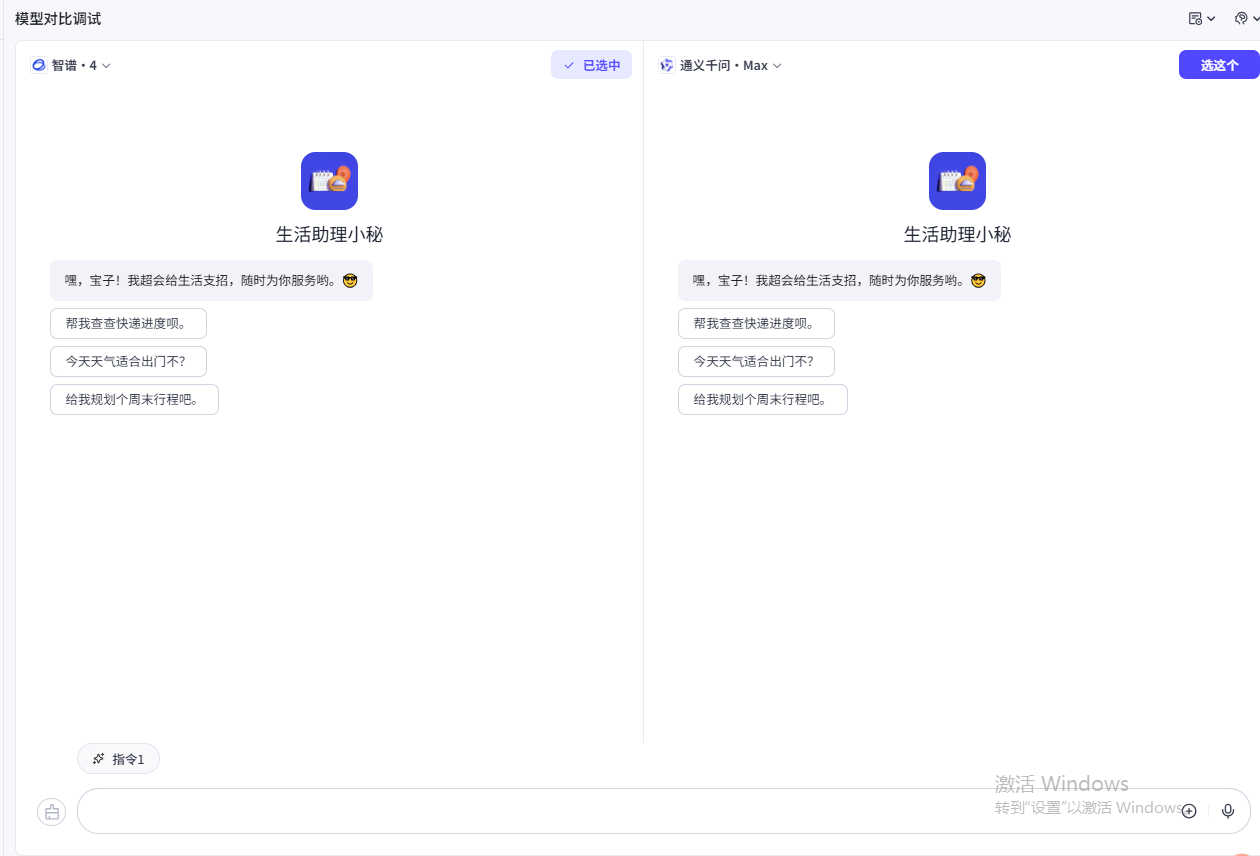
我们进行对话测试一下
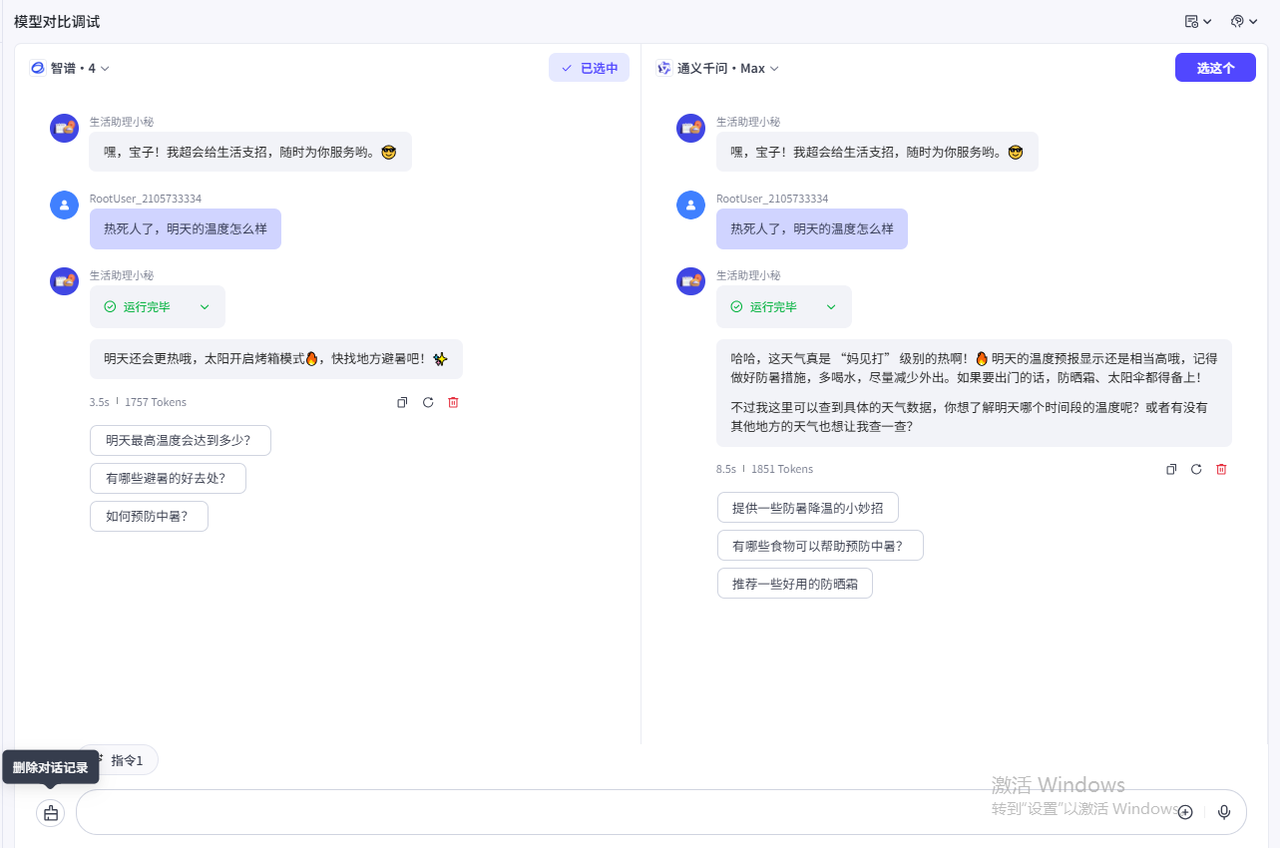
大家最好多测试几轮,根据测试结果选择喜欢的大模型

