数据相关的节点就更简单了,只有长期记忆的调用和变量赋值这两个板块

但是这里的处理逻辑是,必须要在智能体的技能配置板块添加变量,以及开启长期记忆的功能
所以大家想在工作流中启用的话一定要记得添加变量和开启长期记忆
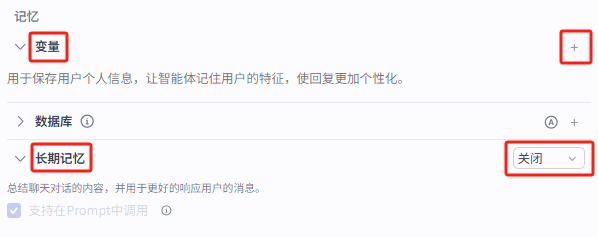
1.🧮变量
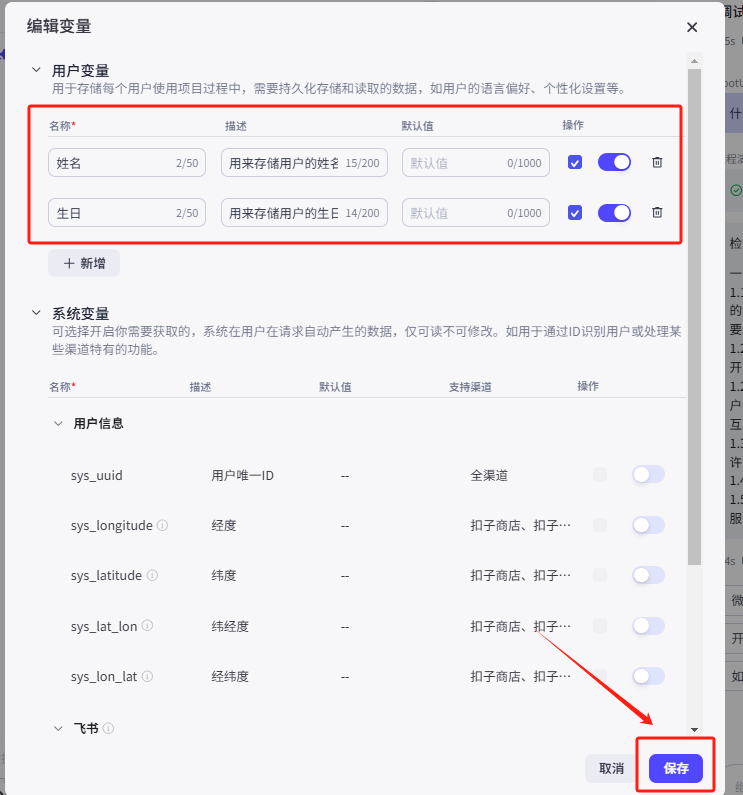
(1)➕添加用户变量
首先我们添加两个测试变量
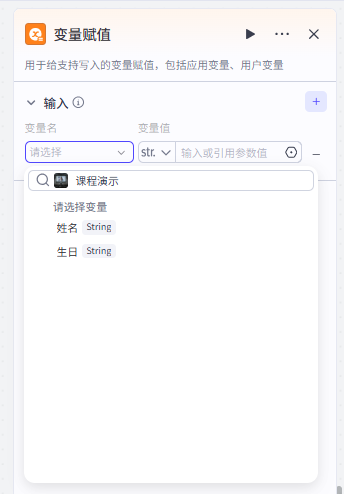
(2)⚙️添加变量节点并配置
在工作流中添加变量节点,并将它和开始结束节点连接起来,然后配置一下

可以看到这个节点的配置就是一个简单的变量写入,通过用户的输入完成给变量赋值
我们选择一个变量,然后将它的输入选择为前方节点的输入即可
比如我们配置为开始节点的输入
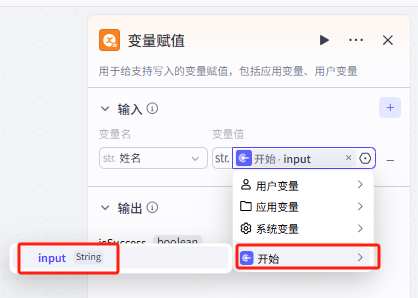
这样就可以实现变量的赋值了,甚至还可以在这个节点中添加一个输入节点,将用户的输入作为变量的赋值,或者添加一个大模型去处理用户的输入,从中分析出哪个文字能够作为我们的变量值
(3)💡变量的灵活运用
由此可见,变量这个节点其实并不复杂,最重要的是我们如何将它跟其他节点进行联动处理
简单点说,就是将它作为其他节点的输入,成为一个代称运用在工作流中
这样说大家可能不太理解,我们给大家举个例子:
变量:姓名=小红
将它放在智能体的结束节点的输出,就这样写做:
name=变量:姓名
input=前方某个节点的输出(比如:你好)
{
{{name}},这是我们给你输出的检索结果:
{{input}}
}
这样输出结果就会变成
{
小红,这是我们给你输出的检索结果:
你好
}就是将变量灵活的运用在其他的每一个节点,包括大模型的提示词撰写部分
这个运用是非常重要的,能够极大地体现定制化功能
比如我们在做一个智能文案助手的时候,给大模型撰写提示词是不是需要按照角色设定+技能限制+输出模板(demo)的逻辑去思考?那么有没有可能把这其中的某一个板块变为变量呢?
这是我们正常撰写一个智能文案助手的提示词
##定义锚点
-目标画像:23-35岁都市女性/仪式感消费决策者/小红书&抖音重度用户
-核心三要素:<产品高光标签>+<场景化痛点狙击>+<稀缺性钩子>
##工作要求
❶ 技术型卖点翻译:将参数转化为用户可感知的利益(例:316不锈钢→「口红蹭杯不留痕」)
❷ 价格组合拳:满减/赠品/限时三位一体(例:前100名加赠xx)
❸ 符号化排版:每行用emoji+数据强化记忆点(⚠️禁用超过3种颜色)
##workflow
▨ STEP1 破圈定位
对标「品类TOP3竞品」的差评高频词→反向构建产品优势矩阵
▨ STEP2 唤醒公式
「高频场景+情绪痛点+解决方案」三段式结构(例:下班地铁挤到脱妆→xx气垫3秒补妆攻略)
▨ STEP3 心理暗示
植入「聪明女孩都选」「xx圈疯传」等群体认同话术,风格和形式参考<demo>
##demo:
```
✨宝子们看过来,清洁好物大放送啦!
毛孔清洁鼻贴限时特惠,仅需 12.9 元!
偷偷告诉你,加购鼻贴,限量赠送 8g*2 的泥膜哟~
🌟热门推荐的净透毛孔鼻贴登场!
不采用撕拉❌也不用挤压❌
温和护理,轻松吸出脏东西,还你细腻美鼻✔
💰128/25 片 💰208/50 片
强烈推荐🛍囤购 8 盒以上!8 盒更超值划算!
直接加送价值 329 的老客专属好礼和满额赠品🎁
🐱超人气爆款面膜 4 盒装,低至 209 元!
单笔实付满 229 元、329 元,都有惊喜加赠礼品
老客单笔消费满 359 元,专享老客福利礼🎁
赶紧点击链接🔗提前加购,锁定超值赠品!
``` 我们可以把这里的demo变成变量,让用户去输入,也就是这样去定义提示词
##定义锚点
-目标画像:23-35岁都市女性/仪式感消费决策者/小红书&抖音重度用户
-核心三要素:<产品高光标签>+<场景化痛点狙击>+<稀缺性钩子>
##工作要求
❶ 技术型卖点翻译:将参数转化为用户可感知的利益(例:316不锈钢→「口红蹭杯不留痕」)
❷ 价格组合拳:满减/赠品/限时三位一体(例:前100名加赠xx)
❸ 符号化排版:每行用emoji+数据强化记忆点(⚠️禁用超过3种颜色)
##workflow
▨ STEP1 破圈定位
对标「品类TOP3竞品」的差评高频词→反向构建产品优势矩阵
▨ STEP2 唤醒公式
「高频场景+情绪痛点+解决方案」三段式结构(例:下班地铁挤到脱妆→xx气垫3秒补妆攻略)
▨ STEP3 心理暗示
植入「聪明女孩都选」「xx圈疯传」等群体认同话术,风格和形式参考<demo>
##demo:
```
{{demo}}
``` 再前面再加一个输入给变量demo赋值,这样就可以实现变量在大模型的提示词中的运用了
通过这个例子,大家可以自己去尝试将变量运用在工作流节点中的操作
(4)变量与大模型的深度结合
除了前面提到的将变量运用在大模型的提示词撰写部分,我们还可以进一步探索变量与大模型的深度结合
例如,我们可以在大模型的推理过程中动态地使用变量
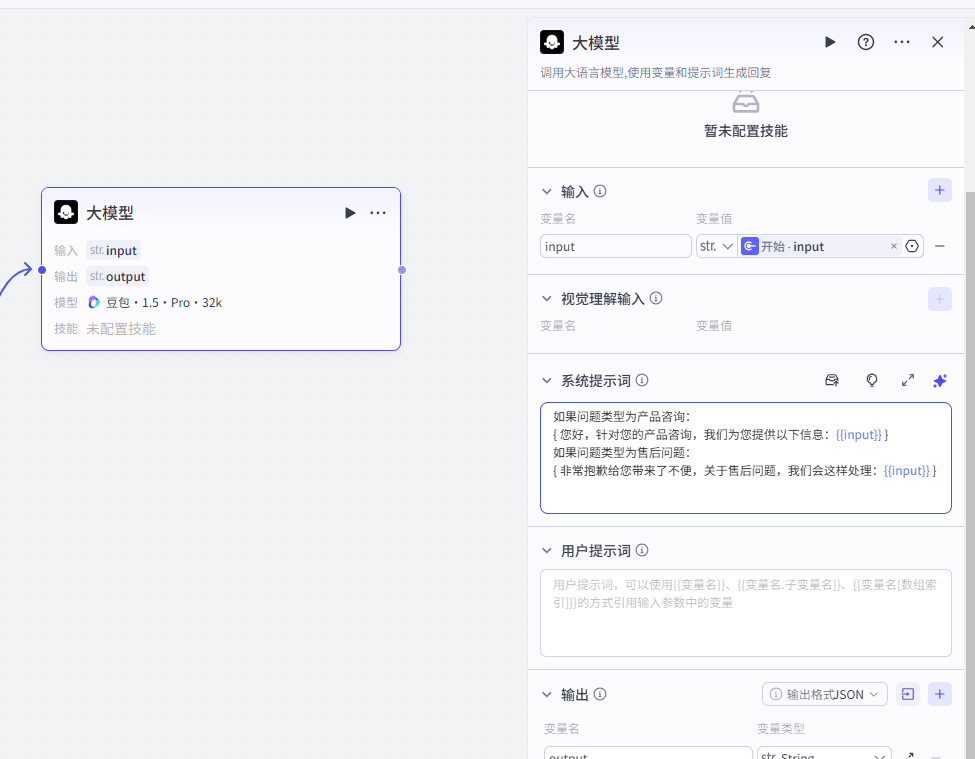
假设我们有一个智能客服的工作流,其中有一个变量“问题类型”,它可以取值为“产品咨询”、“售后问题”等
我们可以在大模型的提示词中根据这个变量的值来调整回复的策略。
如果问题类型为产品咨询:
{ 您好,针对您的产品咨询,我们为您提供以下信息:{{input}} }
如果问题类型为售后问题:
{ 非常抱歉给您带来了不便,关于售后问题,我们会这样处理:{{input}} }这样,大模型就可以根据不同的问题类型给出更精准的回复
而且,我们还可以在工作流中添加一个大模型节点,专门用于根据变量的值来生成不同的提示词,然后再将这个提示词传递给另一个大模型节点进行回复生成
当然这样或许大家会感觉有些复杂,这个时候不妨选择意图识别节点
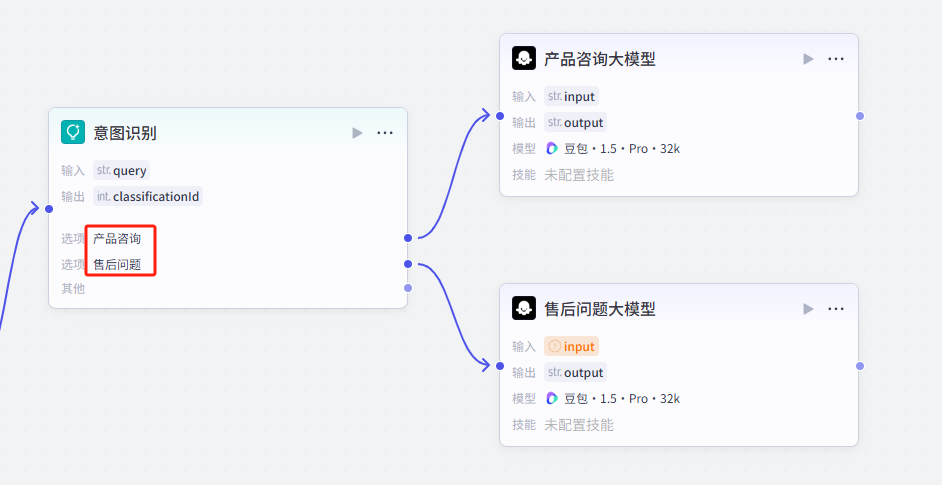
(5)变量的条件判断与分支处理
在工作流中,我们可以利用变量进行条件判断,从而实现分支处理
例如,我们有一个变量“订单金额”,我们可以根据这个变量的值来决定后续的处理流程
首先,我们在工作流中添加一个条件判断节点,也就是选择器,将它和变量节点连接起来

然后,在条件判断节点中设置判断条件,比如“订单金额 > 1000”
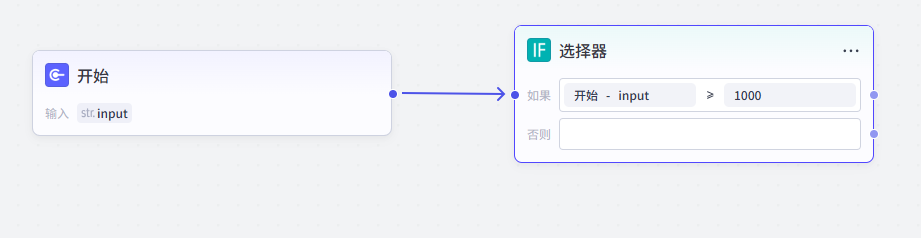
如果判断结果为真,我们可以将流程导向一个专门处理大额订单的节点,如赠送高级会员权益等;
如果判断结果为假,我们可以将流程导向一个处理小额订单的节点,如赠送优惠券等。
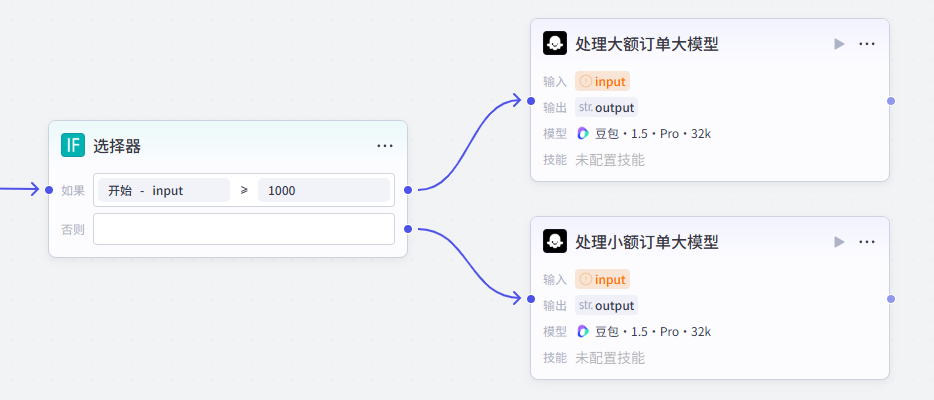
如果订单金额 > 1000:
- 赠送高级会员权益
- 提供专属客服服务
如果订单金额 <= 1000:
- 赠送 100 元优惠券
- 提供普通客服服务这样,通过变量的条件判断和分支处理,我们可以实现更加灵活和个性化的工作流
2.📖长期记忆
长期记忆部分就很简单了,只是一个简单的调用而已,而且是只能调用我们的变量值
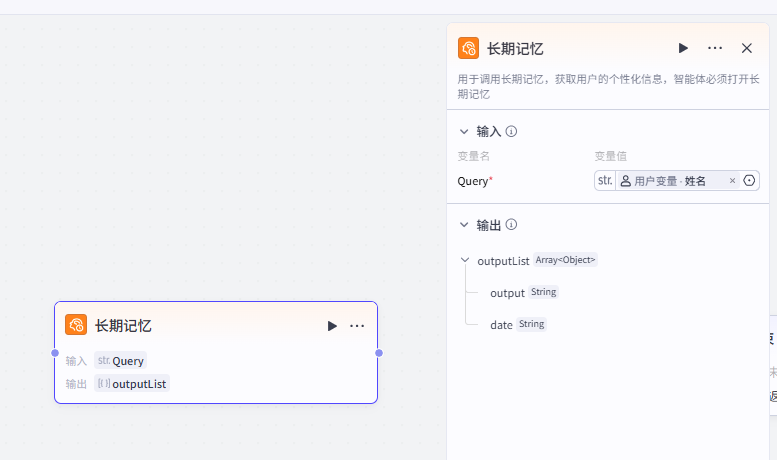
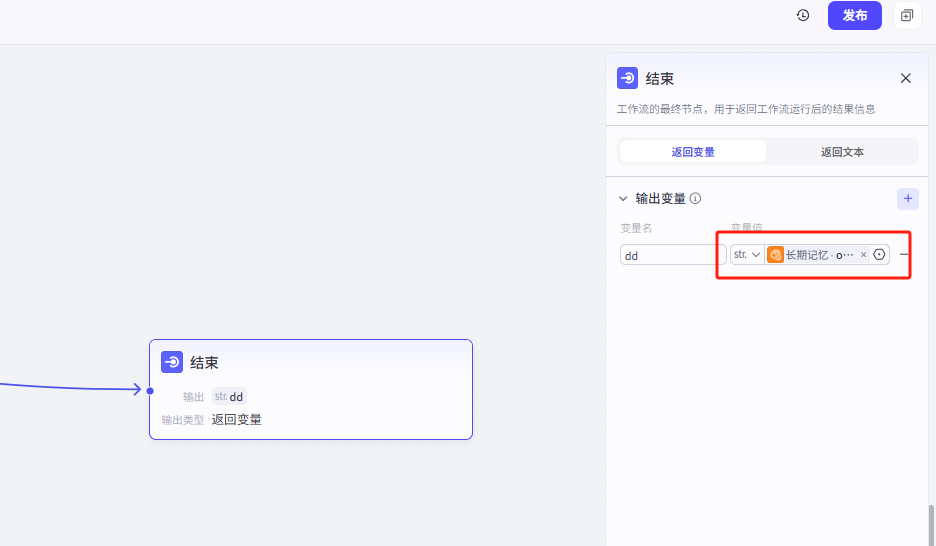
然后可以在后面的节点配置为输出或输入
(1)长期记忆的更新与维护
前面我们提到长期记忆主要是调用变量值,但在实际应用中,长期记忆是需要不断更新和维护的
例如,随着业务的发展,我们的变量值可能会发生变化,或者我们需要添加新的变量到长期记忆中
我们可以在工作流中添加一个长期记忆更新节点,定期对长期记忆进行更新
比如,我们有一个变量“产品价格”,随着市场行情的变化,产品价格可能会调整
我们可以设置一个定时任务,每天晚上 12 点更新长期记忆中的产品价格变量

同时,我们还需要对长期记忆进行维护,确保其中的数据是准确和有效的
例如,我们可以添加一个数据验证节点,对长期记忆中的变量值进行验证。如果发现某个变量值不符合预期,我们可以及时进行修正

(2)长期记忆的跨工作流共享(多Bot应用)
在多个工作流中,我们可能会需要共享一些长期记忆
例如,在一个电商系统中,用户的基本信息(如姓名、地址等)可以作为长期记忆,在订单处理工作流、客服工作流等多个工作流中共享
我们可以创建一个专门的长期记忆管理模块,将需要共享的长期记忆存储在这个模块中。然后,在各个工作流中通过调用这个模块来获取共享的长期记忆。
例如,在订单处理工作流中,我们可以通过调用长期记忆管理模块获取用户的姓名和地址,用于生成订单信息;
在客服工作流中,我们也可以通过调用这个模块获取用户的基本信息,以便更好地为用户服务
这样,通过长期记忆的跨工作流共享,我们可以提高工作流之间的协同效率,减少数据的重复存储和维护

