在上一节课程中,我们打造了一个“AI 创作助手”,让 AI 从一句话创意生成画作与生动的图文描述
这一次,我们把 AI 带进 招聘场景!
HR 在面对大量简历时,需要筛选、分析背景与技能,手工处理既耗时又容易遗漏优秀候选人我们将打造一个 AI 招聘简历分析助手:上传 PDF / Word 简历自动提取教育背景、工作经验、技能、证书,按岗位描述计算匹配度(1~100),并且支持批量分析并输出综合报告
使用文件上传打造 AI 招聘简历分析助手 ——让 AI 自动帮你阅读简历、提炼关键信息并给出招聘建议
Agent体验地址:http://8.137.23.32/chat/WLUO1qPOIuais2BQ
🧭 教学目标
1.使用 Dify 的 文件上传功能 接收并处理本地 PDF / Word 简历文件
2.利用 文档提取器节点 自动解析简历内容
3.结合 LLM 节点 实现结构化信息提取与岗位匹配度分析
4.掌握 迭代节点 批量处理多个文件
✂️ 应用目标拆解:
在招聘过程中,HR 常常需要面对成堆的简历——
先筛掉不符合条件的,再逐一分析候选人的教育背景、工作经验和技能,最后还要给出面试问题建议
如果一份份手工查看,不仅耗时耗力,还容易遗漏优质候选人
这次,我们要做的就是一个 “AI 招聘简历分析助手”: 只需上传候选人的 PDF / Word 简历,AI 就能自动帮你完成:
-
提取教育背景、工作经验、技能、证书等关键信息
-
按岗位描述计算匹配度评分(1-100)
-
给出 3~5 个针对性的面试问题
-
支持批量分析并输出所有简历的综合报告
因此,我们需要完成的任务如下:
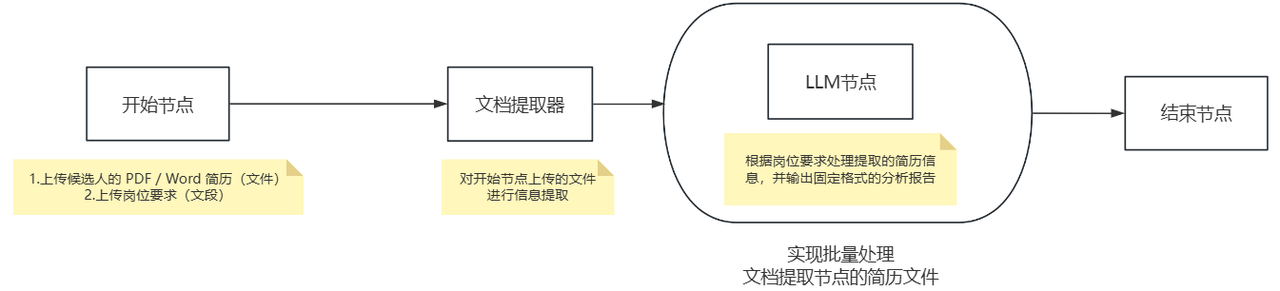
工作流整体截图如下:

⚙️ 创建详解
1:🧱 创建 Agent 应用
在工作室界面,点击创建 空白应用
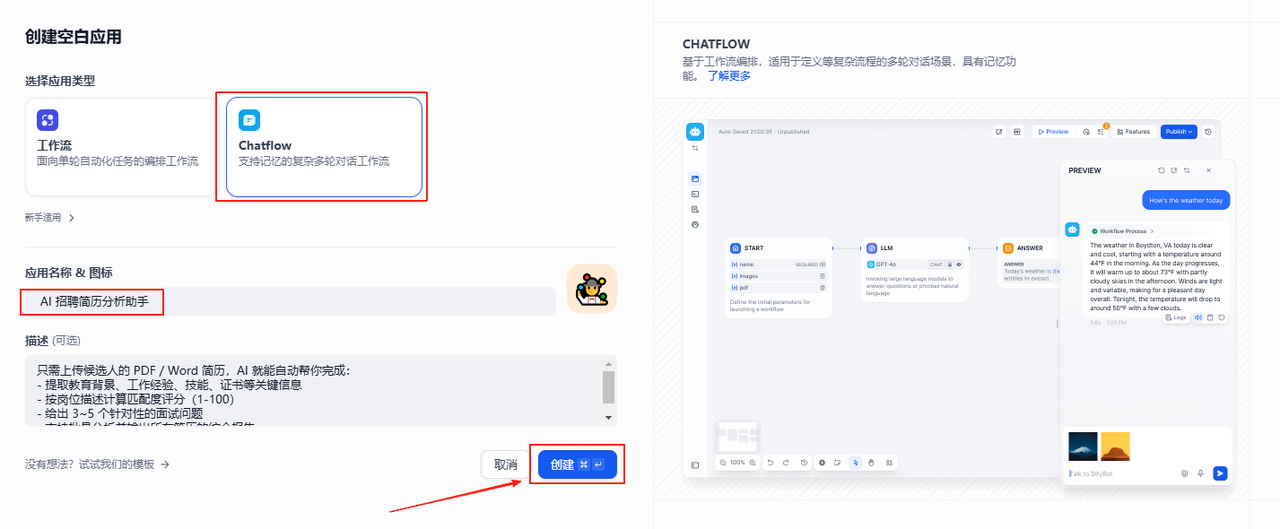
应用类型就选择Chatflow,然后依次填入应用名称和描述,点击一下创建
3:🔩 设计工作流
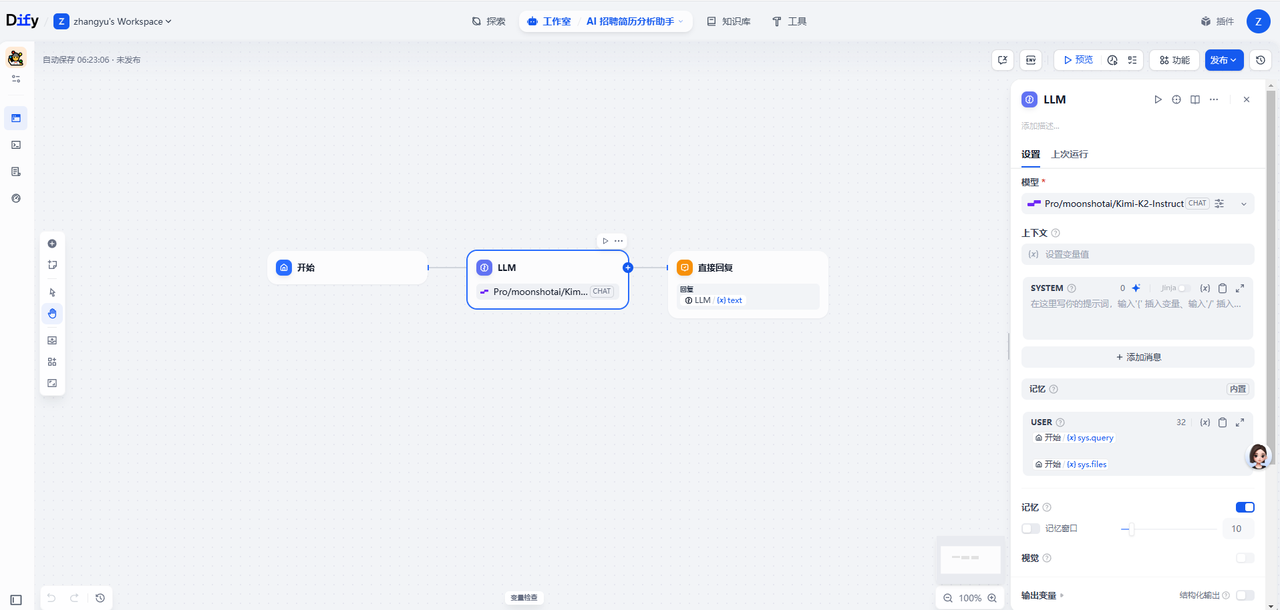
进入工作流编排界面后,默认已经有了开始节点、结束节点和一个LLM大模型节点
首先,我们需要完成单个简历文件的处理逻辑搭建,后续引入一个新的知识:迭代,通过它来完成对上传的多个简历文件的批量处理流程构建,不用删除任何节点,我们直接开始进行工作流的编排
对于还不太清楚迭代作用的同学,想深入了解的话可以点击这个按钮进行学习:点击跳转
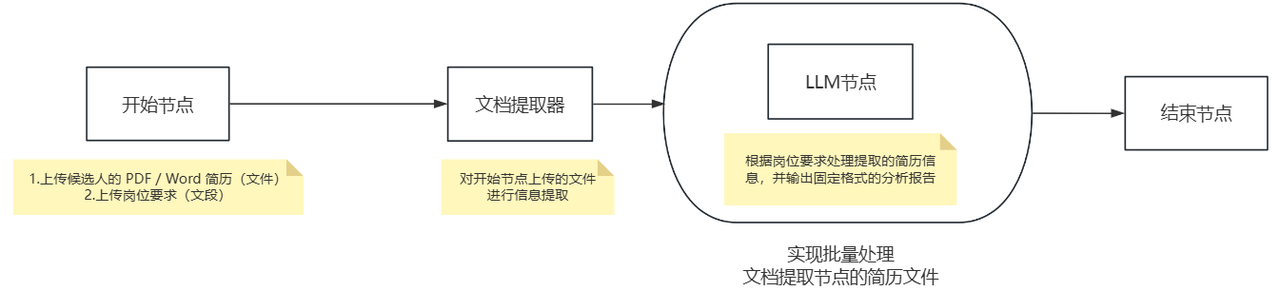
🔷 单个文件处理逻辑的搭建:

单个文件的处理逻辑流程图如上,我们依次开始进行节点的添加和编辑
工作流节点添加:
不用删除LLM节点,直接在左侧面板依次点击,添加一个文档提取器来处理用户在开始节点上传的文档
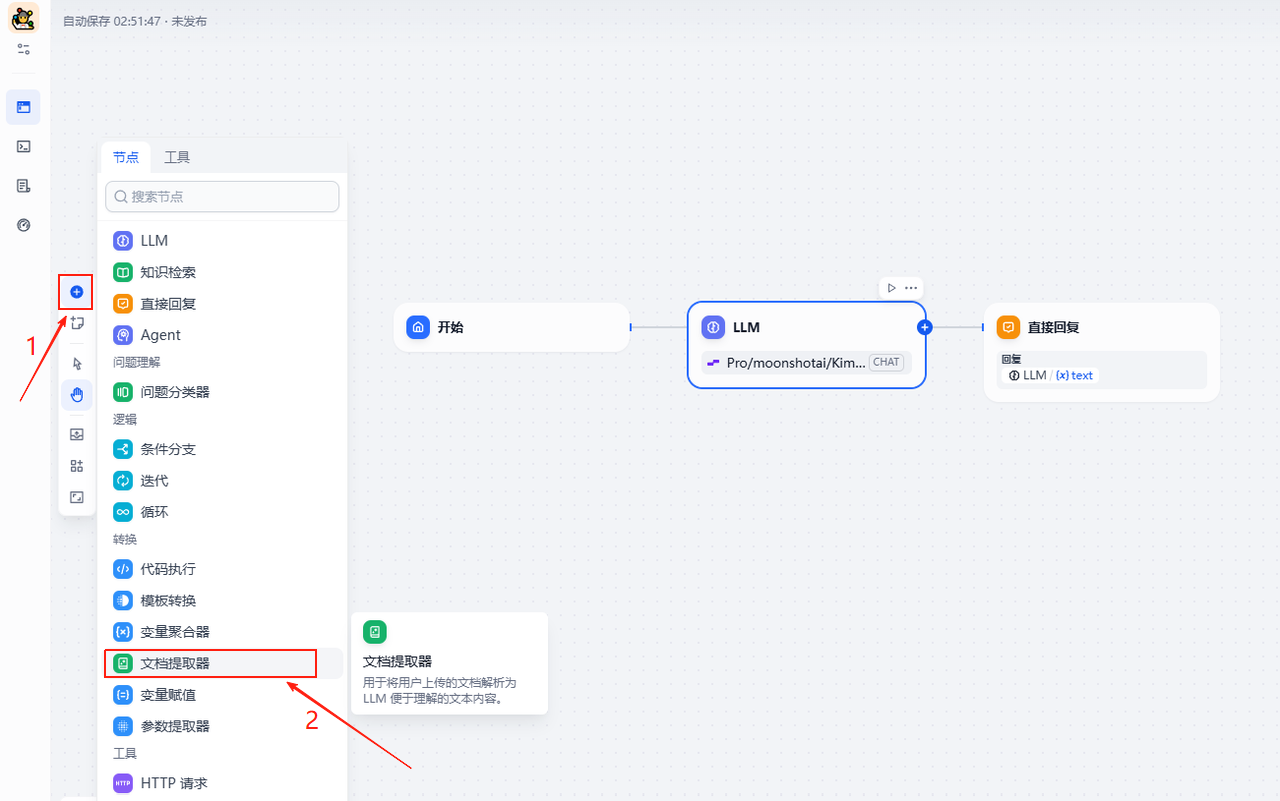
添加进来之后,把它们链接起来,文档提取器放在开始节点之后,LLM节点之前

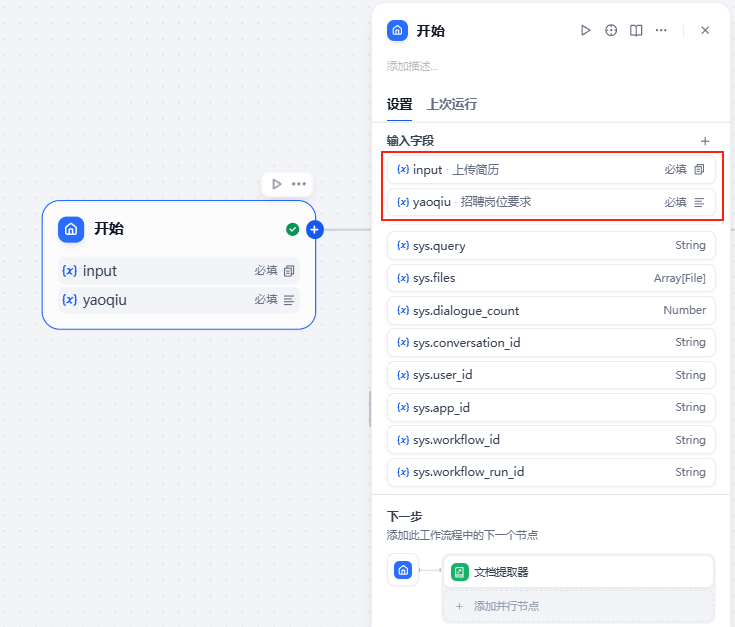
开始节点:
点击一下开始节点,在右侧弹出的弹窗-输入字段板块点击+
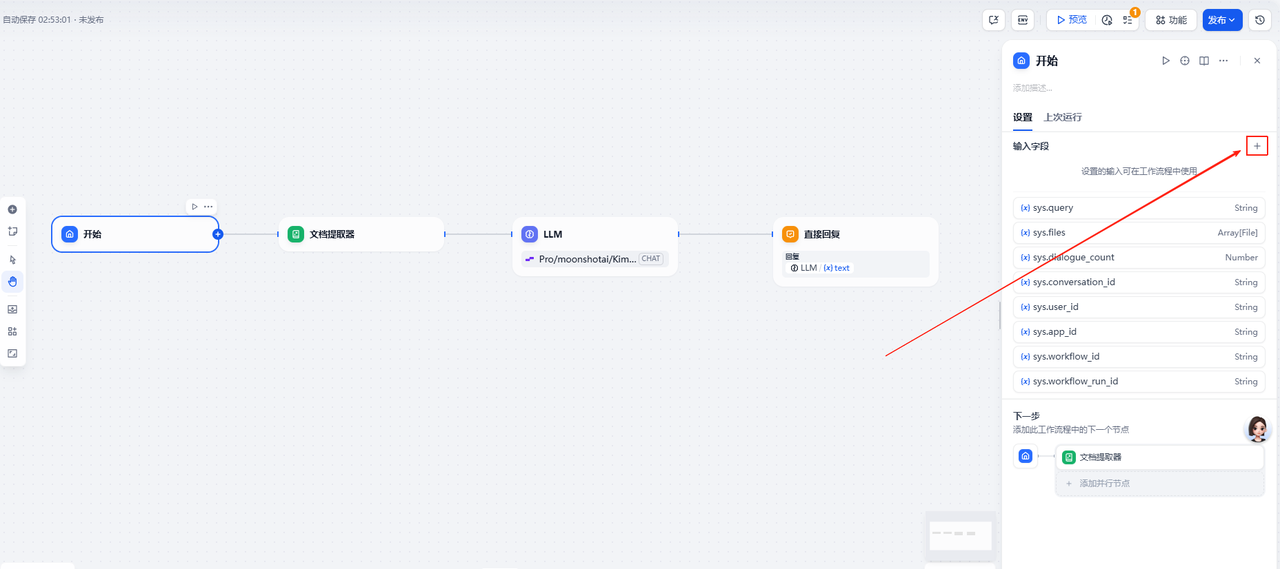
接下来如图所示,依次完成该输入变量的编辑
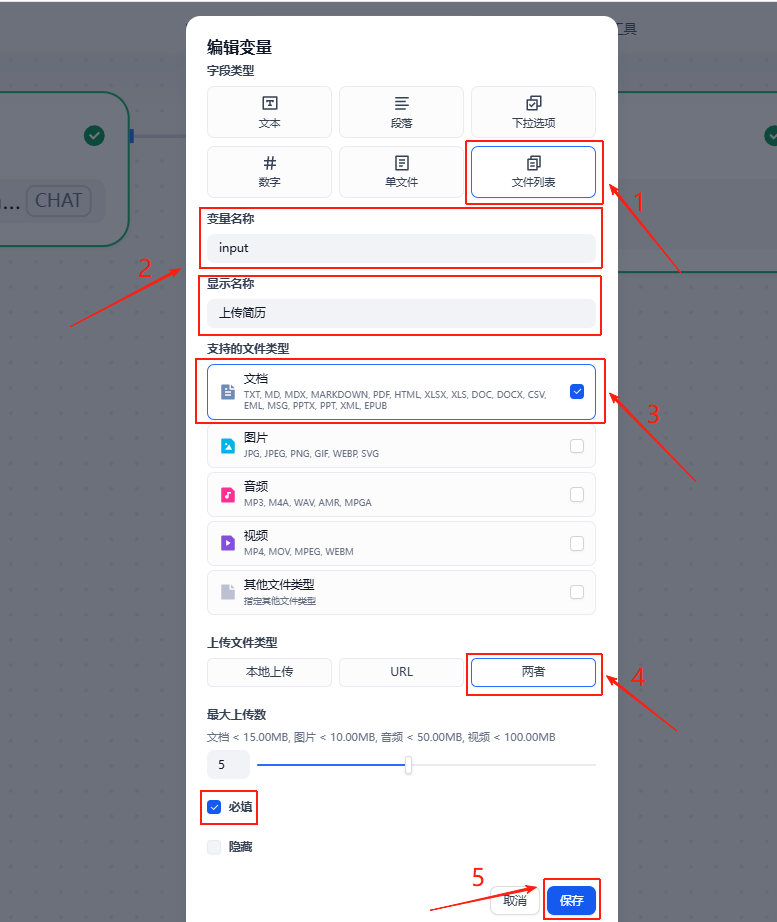
该变量主要是用来接收用户上传的应聘人员简历,所以是文件类型,并且只支持文档
当然,文档提取器是支持读取Html链接的,如果你的应聘人员简历是一个html,也可以通过文档提取器节点读取,但是该案例主要是在讲解如何使用文件上传打造AI招聘助手,所以就不对html的应用展开考虑,不过感兴趣的朋友可以自己研究一下,对该案例进行优化,实现文件、html多读取的AI招聘助手
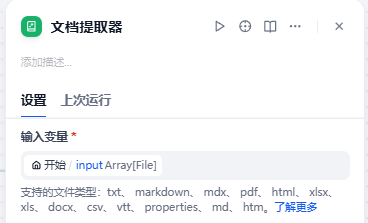
然后再依图步骤添加一个新的变量,用来接收用户的招聘岗位要求
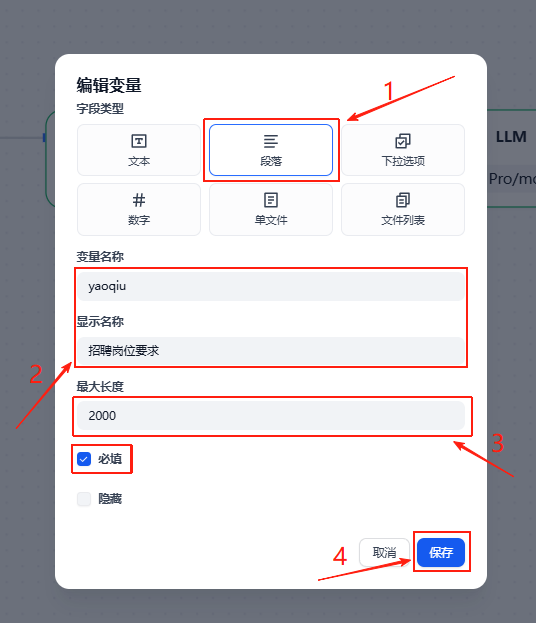
设置好之后就是这样
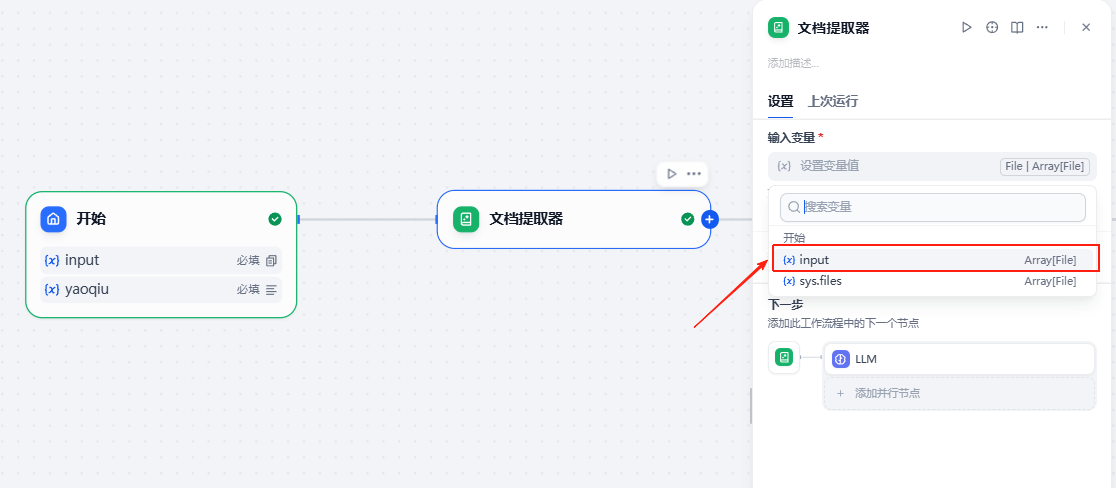
文档提取器:
文档提取器节点比较特殊,只需要设置该节点的输入即可,输出是固定的,我们选择输入为开始节点的input
LLLM节点:
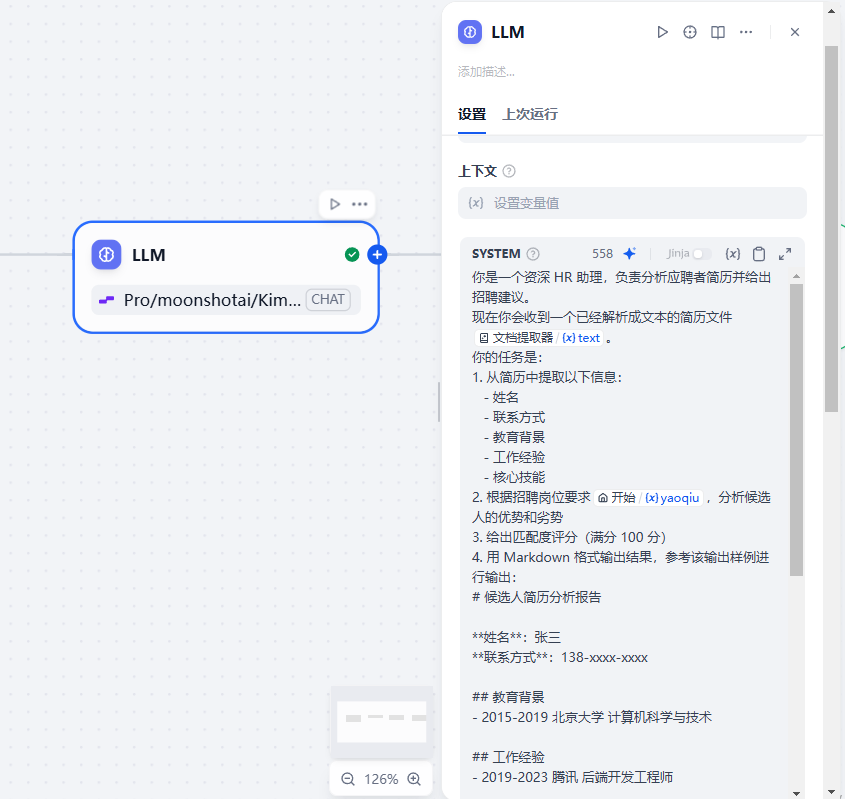
接下来是LLM节点,我们需要设置模型和提示词
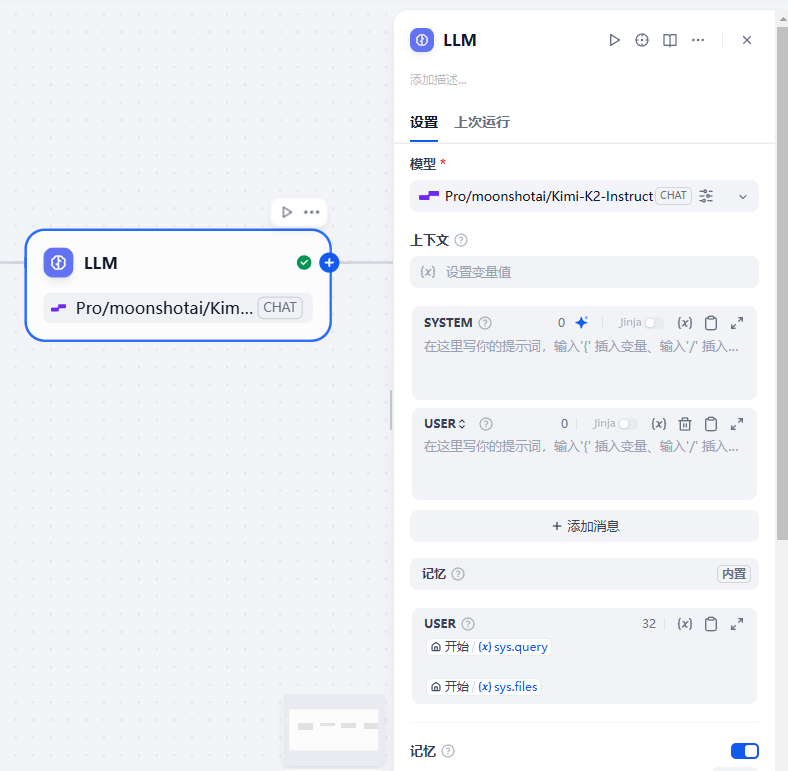
我们的模型使用的是硅基流动的Pro/moonshotai/Kimi-K2-Instruct

然后输入我们写好的提示词,大家可以参考下:点击复制提示词
结束节点:
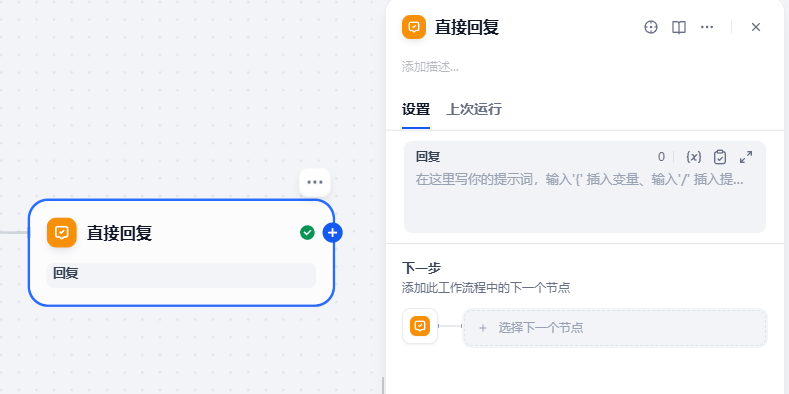
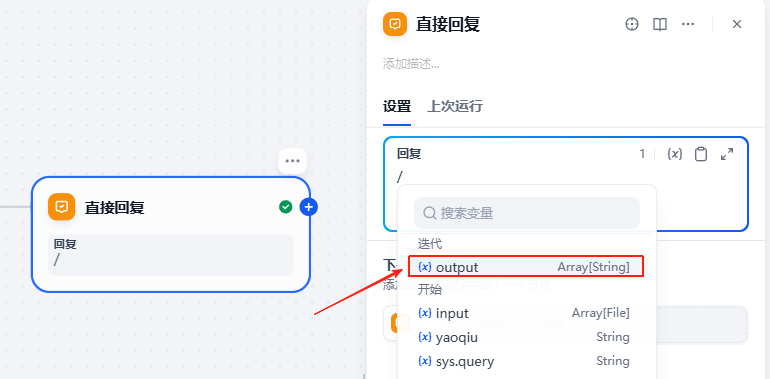
结束节点直接回复LLM的输出即可,输入
/后,点击LLM的text为输出即可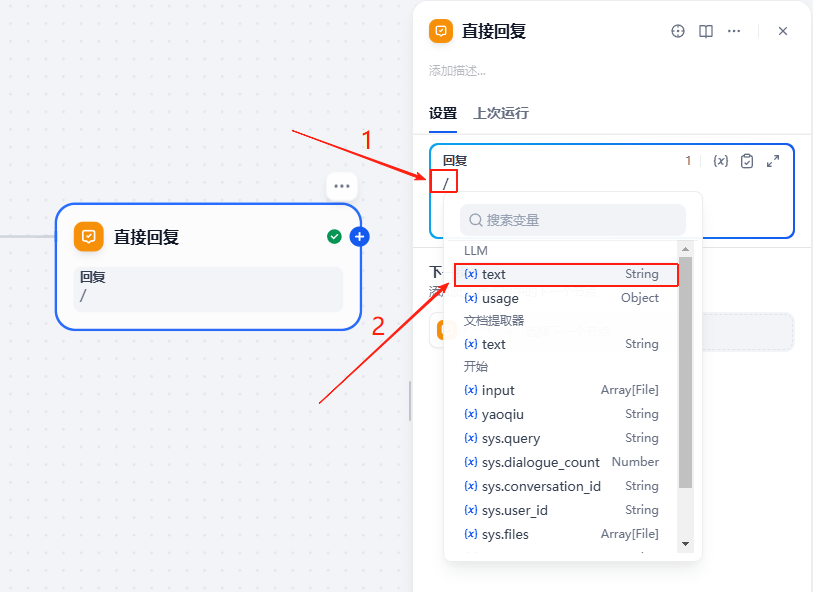
工作流测试:

到此为止,单个文件处理逻辑的搭建已经全部完成,我们测试一下
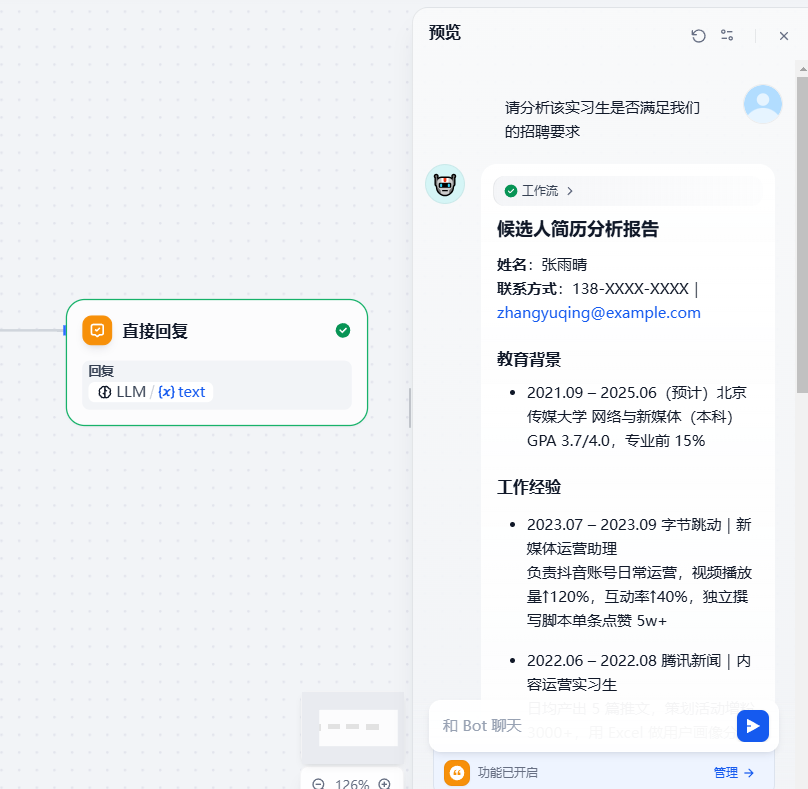
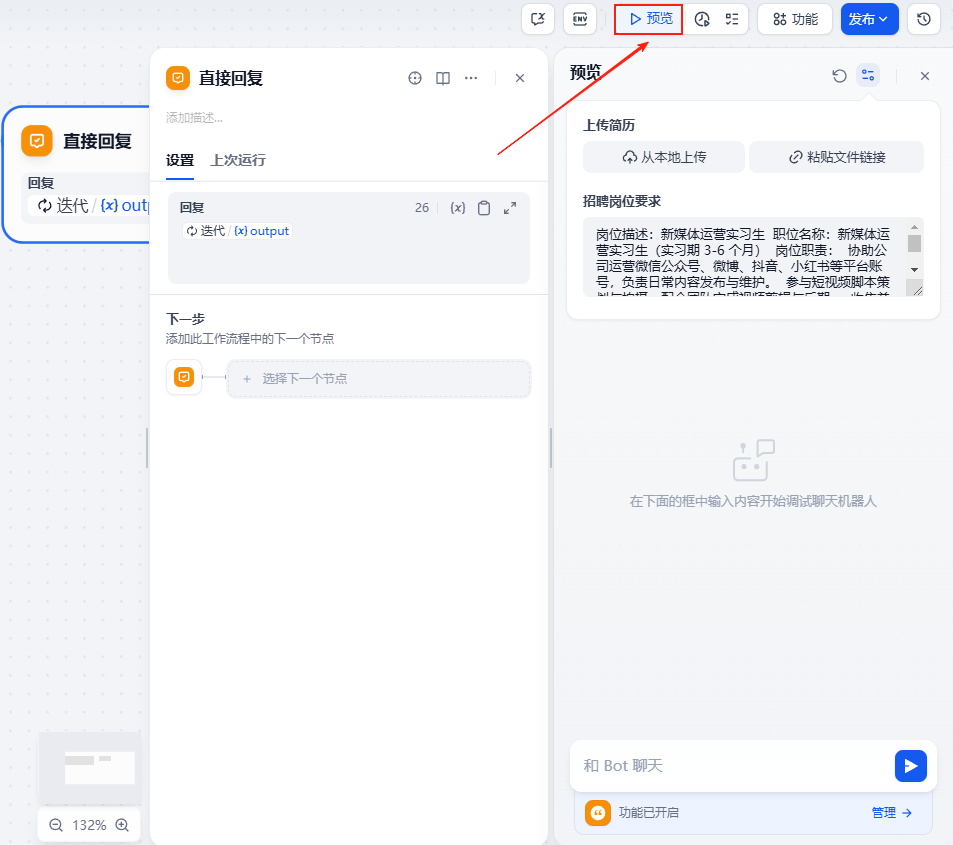
点击预览,然后在弹出来的窗口中依次上传招聘人员的简历文件,以及我们的岗位要求,再输入需求,点击按钮
大家需要相关测试文件和数据的话,点击这里进行获取:点击跳转
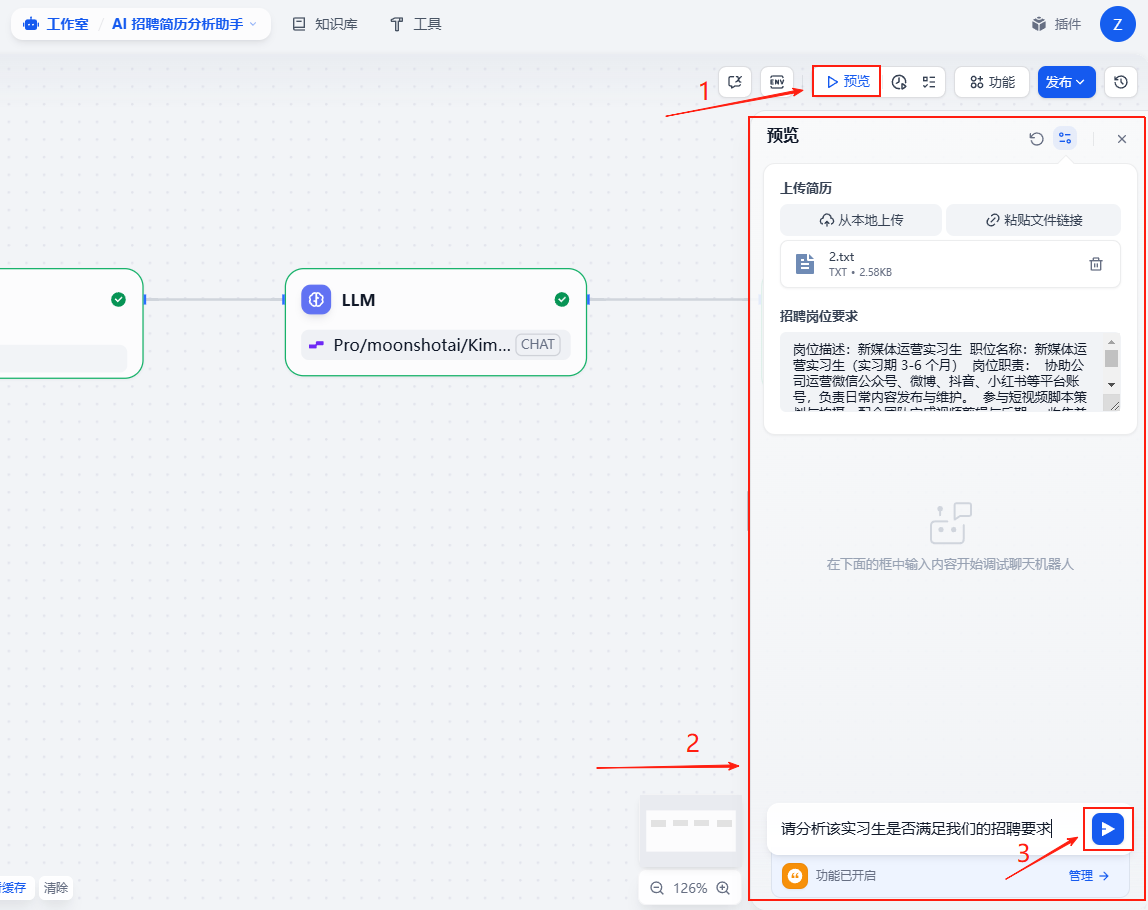
可以看到工作流按照我们的预期顺利输出了整理后结构化的招聘人员简历,以及相对应的匹配评分

🔷多个文件处理逻辑的搭建
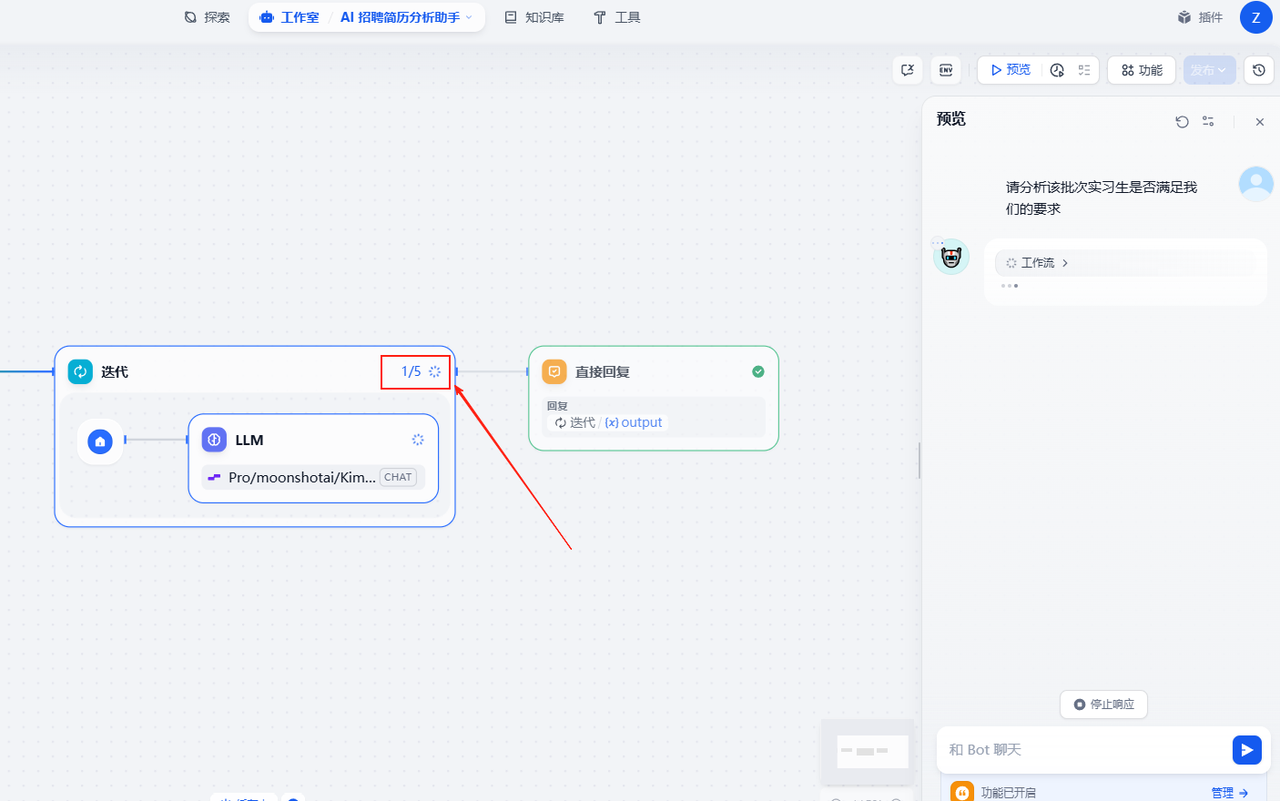
多个文件的处理逻辑其实很简单,就是使LLM节点实现批量处理,这里就要用到一个新的知识点——迭代
点击左侧的+,然后在弹窗中找到迭代,点击一下把它添加到工作流中
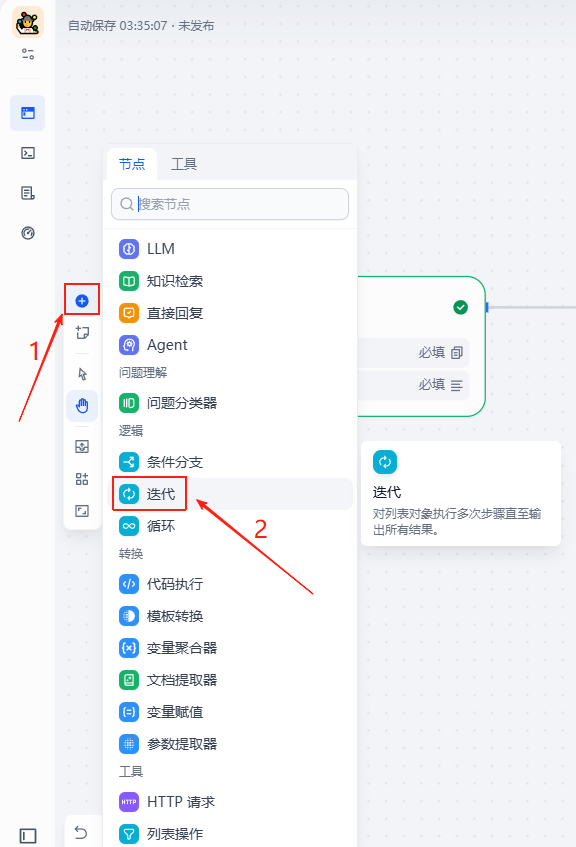
添加进工作流之后就是这样,我们无法将原本的节点直接加进去
所以这里需要重新添加一下LLM节点,然后删除原来的LLM,接下来就需要重新配置一下该工作流中的节点

迭代:
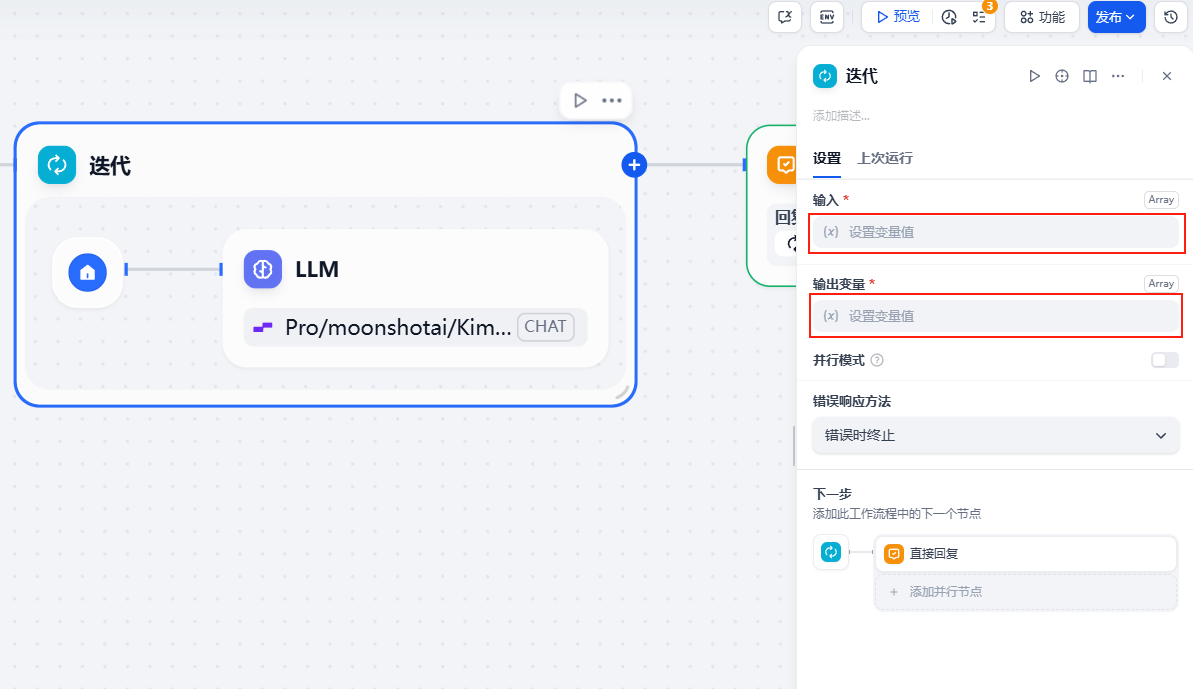
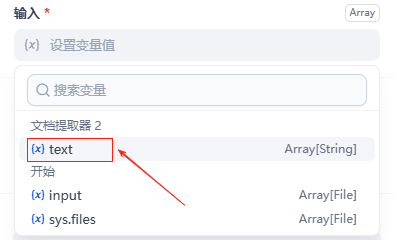
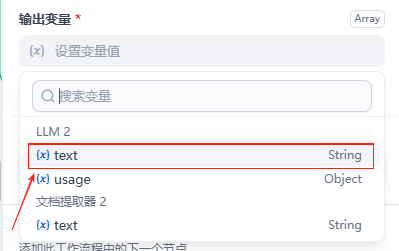
点击迭代,然后设置一下右侧弹窗中的输入和输出
输入为文档提取器的 text 输出为迭代节点内的大模型节点的 text
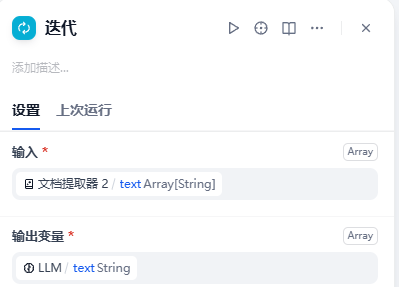
设置好之后就是这样
LLM节点:
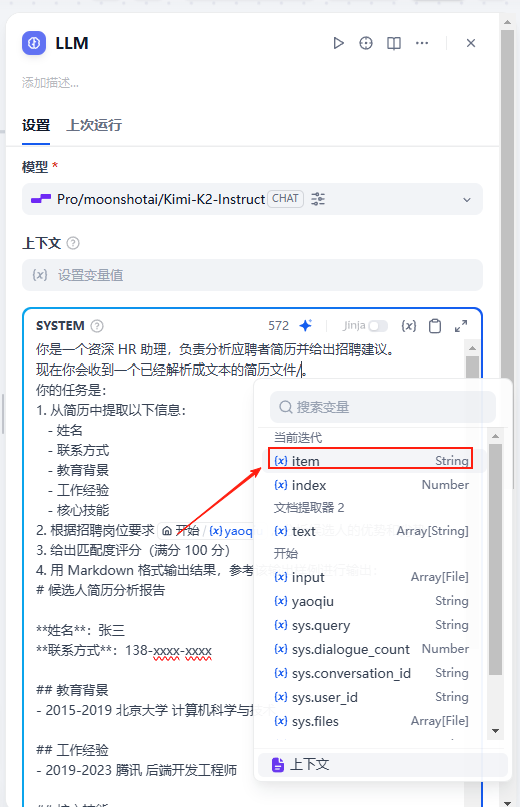
这里的LLM提示词不太一样,我们的简历文件来源是迭代中的item,点击复制提示词:点击复制提示词
大家注意一下,现在操作的是迭代节点里的内容所以这里的 item 是节点的输入,链接的是我们在上一步设置的输入参数,在迭代中,它有了新的变量名称 item如果我们没有给上一步的迭代节点配置好输入内容,那这个 “开始节点” 就会处于没有任何输入的状态哦
结束节点:
结束节点,需要选择迭代的 output 为输出
4:🚀 测试应用
接下来直接点击预览进行测试
然后依次上传我们的测试简历文件5个,以及招聘岗位要求和输入文字,然后运行一下
如果大家需要我们的测试文件,点击这里去进行下载哦:点击跳转
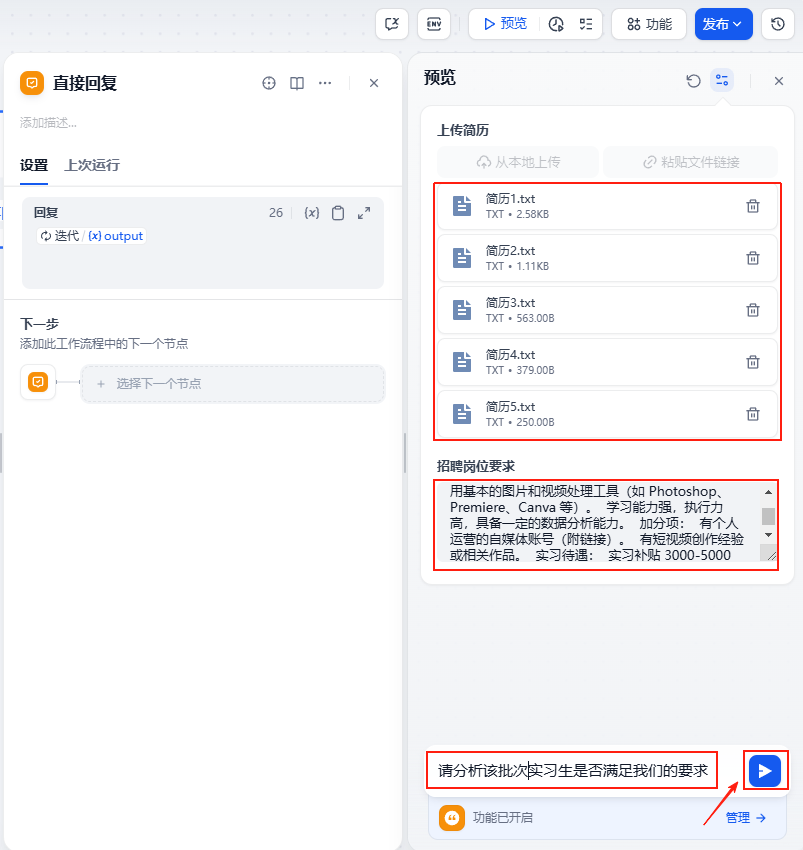
可以看到工作流开始运行,迭代是依次运行的,这里还会显示迭代的次数
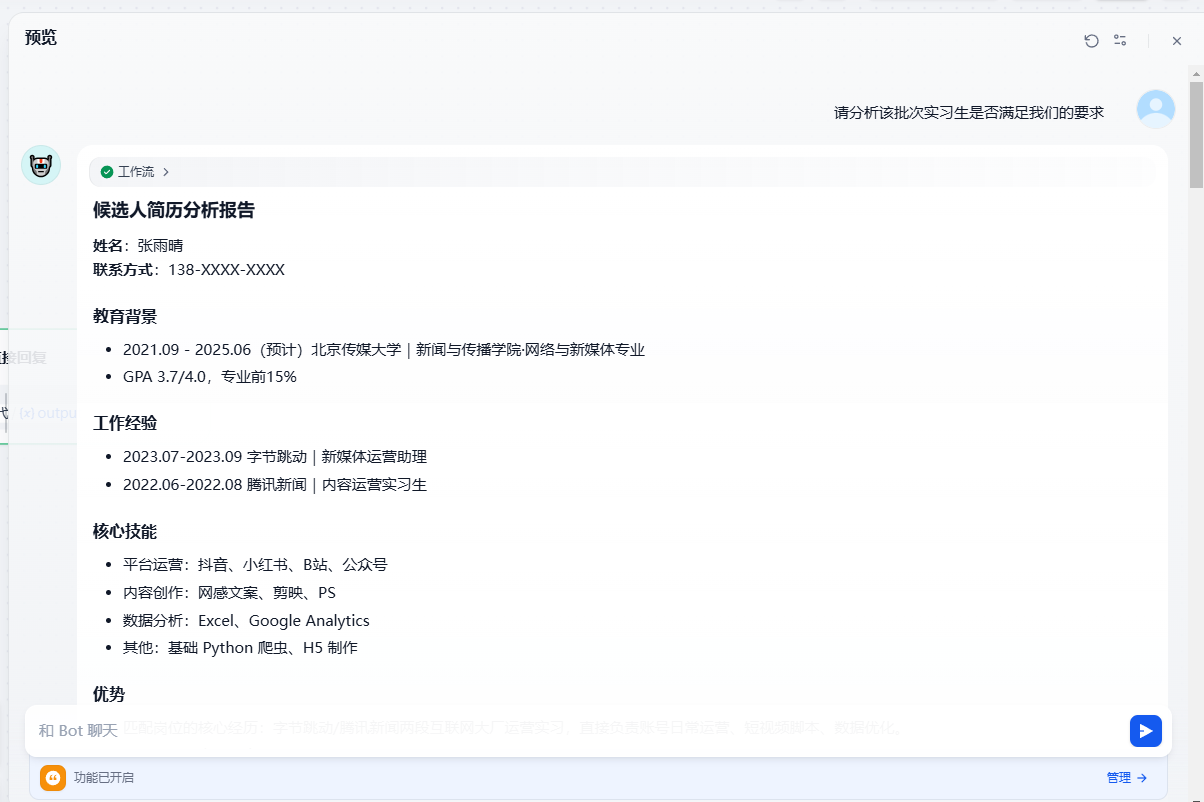
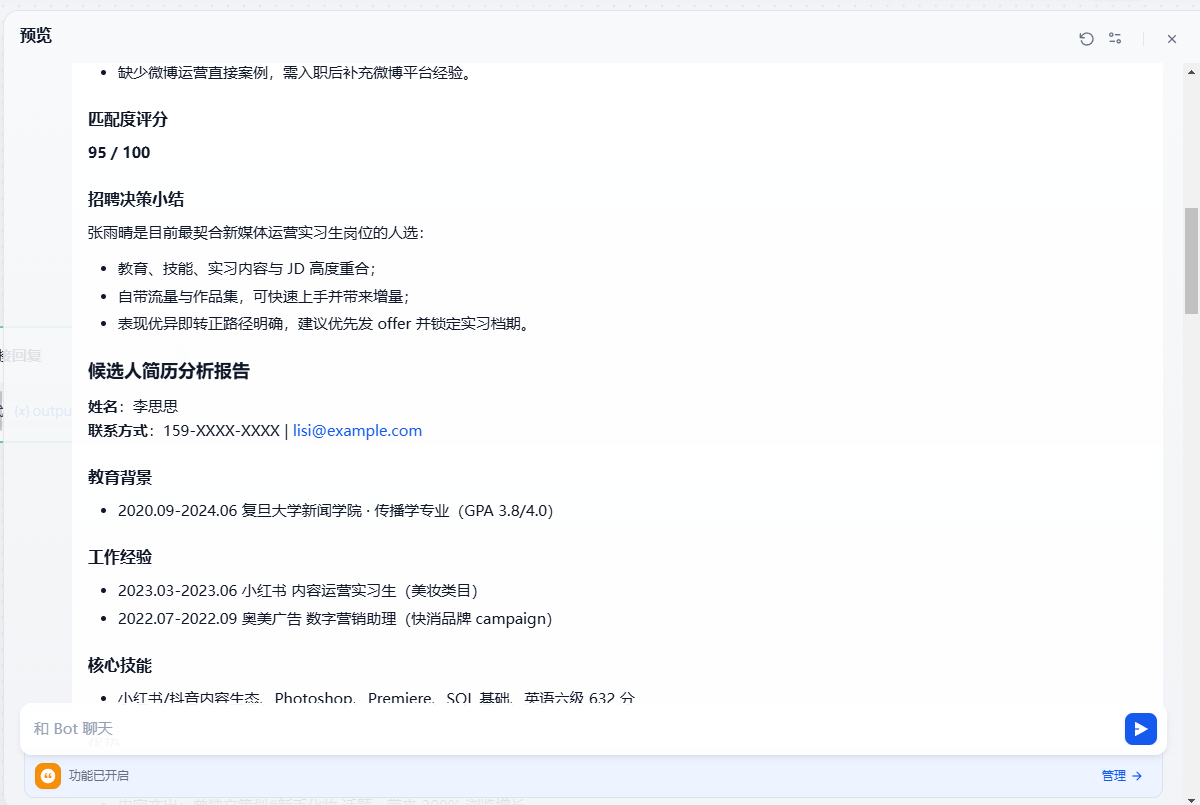
可以看到,我们的 Agent 已经能够顺利完成批量简历的结构化评分与转写输出,在测试中表现相当稳健
不过,要真正将它投入到真实的业务场景中,还有很大的优化和扩展空间
例如,你可以为它加入更多“加分技能”:
-
生成批量评分排行榜 —— 一眼锁定 Top 3 候选人,筛选更高效
-
自动推送分析结果 —— 通过 Webhook 或邮件,第一时间送达 HR 手中
-
中英文混合简历处理 —— 自动检测并翻译,轻松跨语言分析
至于这些进阶玩法,就留给大家去探索和实践吧!

